AuroraからS3への定期的なエクスポートのための手順とLambdaコードサンプル
AuroraからS3へ定期的にDBの内容をエクスポートする方法
Auroraのデータを活用するためのデータエクスポートについて
アプリケーションなどをクラウド上に構築する際、Amazon Auroraを使用することは多いかと思います。
安心のマネージドかつ高いスケーラビリティ、そしてMySQL / PostgreSQLと互換性がある、ということで安定した構成でのアプリケーション構築が可能だと思います。
構築されたアプリケーションにおいてAuroraに溜まっていくデータを分析したいシチュエーションでは、いったんAuroraのデータをなんらかの分析用基盤にエクスポートするのが基本かと思います。
本記事ではその方法について扱います。 定期的に実行するためのコードサンプルもあります。
Auroraのエクスポートは2種類あるので気をつけて
「AuroraからS3へのエクスポート」とかで検索すると 2つの公式ドキュメントがヒットします。
があって、どちらもページのレイアウトは同じなので同時に開いていると混乱してしまいかねません。
知っておきたい重要なことは一つだけです。
「現在AuroraからS3へは “スナップショットのデータ” または “クラスターそのもののデータ” を吐き出せる」
ということです。
クラスターそのもののデータを吐き出せるようになったのが、「Amazon Aurora が S3 へのクラスターのエクスポートのサポートを開始」の記事にあるとおり 2022年10月ですので割と最近です。
それまでは、スナップショットをエクスポートするのが基本でした。定期的にスナップショットを作っていない場合は、エクスポートのために作る必要があったわけです。
しかし、 今はそのままクラスタのARNをエクスポート対象として指定できますので、エクスポートのためだけのスナップショット作成は不要です。
まずこれがハマりポイントです。なぜかというと、検索すると 2022年10月より前の記事ではスナップショット作成の手順が入ってくるから ですね。
実際の手順
ここからは、実際の手順についてまとめます。
基本的には先ほどの Amazon S3 への DB クラスターデータのエクスポート のページの手順に沿うだけなのですが、今一つわかりにくいところもあるので、具体的にどうするかの設定やコードも交えておきます。
(※設定例ですので、環境に合わせてうまく調整してください)
1. AuroraエクスポートのためのRoleを作成する
まずAuroraからのエクスポートタスクに使用するRoleを作成します。
信頼されたエンティティ として下記を設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "export.rds.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {}
}
]
}
許可ポリシー として下記を設定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AuroraExportS3Policy",
"Effect": "Allow",
"Action": [
"s3:PutObject*",
"s3:ListBucket",
"s3:GetObject*",
"s3:DeleteObject*",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::[エクスポート先のバケット名]",
"arn:aws:s3:::[エクスポート先のバケット名]/*"
]
}
]
}
作成したRoleのARNを記録しておきます。
2. KMSキーを作成する
対象なキーとしてKMSキーを作成し、ARNを記録します。
arn:aws:kms:[リージョン名]:[プロジェクトID]:key/[キーID]
のようになります。最後の [キーID] は定期実行用のコードで使用します。
3. Lambda実行用のRoleを作成する
Lambda実行に割り当てるロールについても KMS / Aurora / IAM 用に適切なロールを作成する必要があります
信頼されたエンティティ として下記を設定
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
許可ポリシー として AWSLambdaBasicExecutionRole に加えて(※ここをもう少し絞るなどしても良いかと思います)
新規ポリシーを
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AuroraExportForLambdaPolicy",
"Effect": "Allow",
"Action": [
"kms:DescribeKey",
"kms:CreateGrant",
"iam:PassRole",
"rds:StartExportTask"
],
"Resource": [
"[手順2で作成したKMSのARN]",
"[Aurora クラスタのARN]",
"[手順1で作成したエクスポートタスク用のRoleのARN]"
]
}
]
}
で定義し、Lambda実行用ロールに指定します。
ここでのポイントは、 rds:StartExportTask に加えて KMSへのアクセス権やIAM RoleをPassする権限 が必要ということですね。
4. 定期実行用のLambda関数を仕込む
手順3で作成したLambda実行用Roleを指定した上でExportタスクをトリガするLambda関数を作成します。
下記にPython 3.12およびNode.js 20 (mjs)でのサンプルコードを載せておきます。
あくまで簡易的なものなので、ここにエラー検知の仕組みを加えるなどの微調整を行っていただくのが良いかと思います。
Python 3.12版 (boto3 の start_export_task を使います)
import boto3
import datetime
from zoneinfo import ZoneInfo
rds_client = boto3.client('rds')
def lambda_handler(event, context):
datetime_now = datetime.daetime.now(ZoneInfo("Asia/Tokyo"))
# エクスポートタスクのID(時刻をyyyyMMdd-HHで末尾に付与)
export_task_id = f"lambda-{datetime_now:%Y%m%d-%H}"
# エクスポート先のS3バケット
s3_bucket_name = "[エクスポート先のバケット名]"
# RDSクラスタのARN
rds_source_arn = "[RDSクラスタのARN]"
# RDSエクスポートのためのIAM RoleのARN
iam_role_for_export_arn = "[RDSエクスポート用IAM RoleのARN]"
# KMSのキーID(ARN末尾のUUID)
kms_key_id = "[KMSのキーID]"
# S3バケットのプレフィクス(スラッシュは末尾に勝手に付与される)
s3_prefix = f"parquet/export-{datetime_now:%Y%m%d-%H}"
try:
response = rds_client.start_export_task(
ExportTaskIdentifier=export_task_id,
SourceArn=rds_source_arn,
S3BucketName=s3_bucket_name,
IamRoleArn=iam_role_for_export_arn,
KmsKeyId=kms_key_id,
S3Prefix=s3_prefix
)
return {
'statusCode': 200,
'body': f"Export task started successfully: {response['ExportTaskIdentifier']}"
}
except Exception as e:
return {
'statusCode': 500,
'body': f"Error starting export task: {str(e)}"
}
Node.js 20版 (index.mjs想定) (JS SDKのStartExportTaskCommand を使います)
import { RDSClient, StartExportTaskCommand } from "@aws-sdk/client-rds";
const rdsClient = new RDSClient();
export const handler = async (event) => {
// 現在の日時を使ってエクスポートタスクIDを生成(時刻をyyyyMMdd-HHで末尾に付与)
const now = new Date();
const exportTaskId = `lambda-${now.getFullYear()}${(now.getMonth() + 1).toString().padStart(2, '0')}${now.getDate().toString().padStart(2, '0')}-${now.getHours().toString().padStart(2, '0')}`;
// エクスポート先のS3バケット
const s3BucketName = '[エクスポート先のバケット名]';
// RDSクラスタのARN
const rdsSourceArn = '[RDSクラスタのARN]';
// RDSエクスポートのためのIAM RoleのARN
const iamRoleForExportArn = '[RDSエクスポート用IAM RoleのARN]';
// KMSのキーID(ARN末尾のUUID)
const kmsKeyId = '[KMSのキーID]';
// S3バケットのプレフィクス(スラッシュは末尾に勝手に付与される)
const s3Prefix = `parquet/export-${now.getFullYear()}${(now.getMonth() + 1).toString().padStart(2, '0')}${now.getDate().toString().padStart(2, '0')}-${now.getHours().toString().padStart(2, '0')}`;
const params = {
ExportTaskIdentifier: exportTaskId, // 生成したエクスポートタスクIDを使用
SourceArn: rdsSourceArn,
S3BucketName: s3BucketName,
IamRoleArn: iamRoleForExportArn,
KmsKeyId: kmsKeyId,
S3Prefix: s3Prefix,
};
try {
const command = new StartExportTaskCommand(params);
const data = await rdsClient.send(command);
return {
statusCode: 200,
body: JSON.stringify({
message: 'Export task started successfully',
exportTaskIdentifier: data.ExportTaskIdentifier
}),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({
message: 'Error starting export task',
error: error.message
}),
};
}
};
いずれも lambda-yyyyMMddHH という名前のエクスポートタスクで、S3バケット内に parquet/export-yyyyMMddHH というprefixを付けた上でデータをエクスポートします。
5. 定期実行用トリガを仕込む
テスト実行してみて問題無くエクスポート用のタスクがトリガできていたら、あとはこのLambda関数に対してトリガをEventBridgeとして定期実行すればOKです。
いくつかの注意点について
以上が手順ですが、追加でいくつかの注意点について触れておきます。
エクスポート形式のParquetにはスキーマが含まれている
今回の手順では、 Parquet という形式でデータをエクスポートします。
形式としてはcsvなどに比べるとマイナーなほうかなと思うのですが、Parquetにはスキーマ情報も含まれます。
よって、 BigQueryなどに取り込む際も特にスキーマの指定は不要です。 楽でいいですよね。
(結局BigQuery側で型の微調整をいれたりしますけどね…)
S3バケットのライフサイクルルール
エクスポートの頻度にもよりますが、エクスポートしたデータをずっと残す必要はないことのほうが多いかと思いますので、 基本的にはS3バケットのライフサイクルルールで、数日後には自動削除されるような形をとるのが好ましいかと思います。
吐き出されたファイルは分割されている
エクスポートに成功した場合の .gz.parquet ファイルは複数に分割されています。
よって、取り込む際はすべての *.gz.parquet ファイルを取り込むように指定するのが好ましいです。
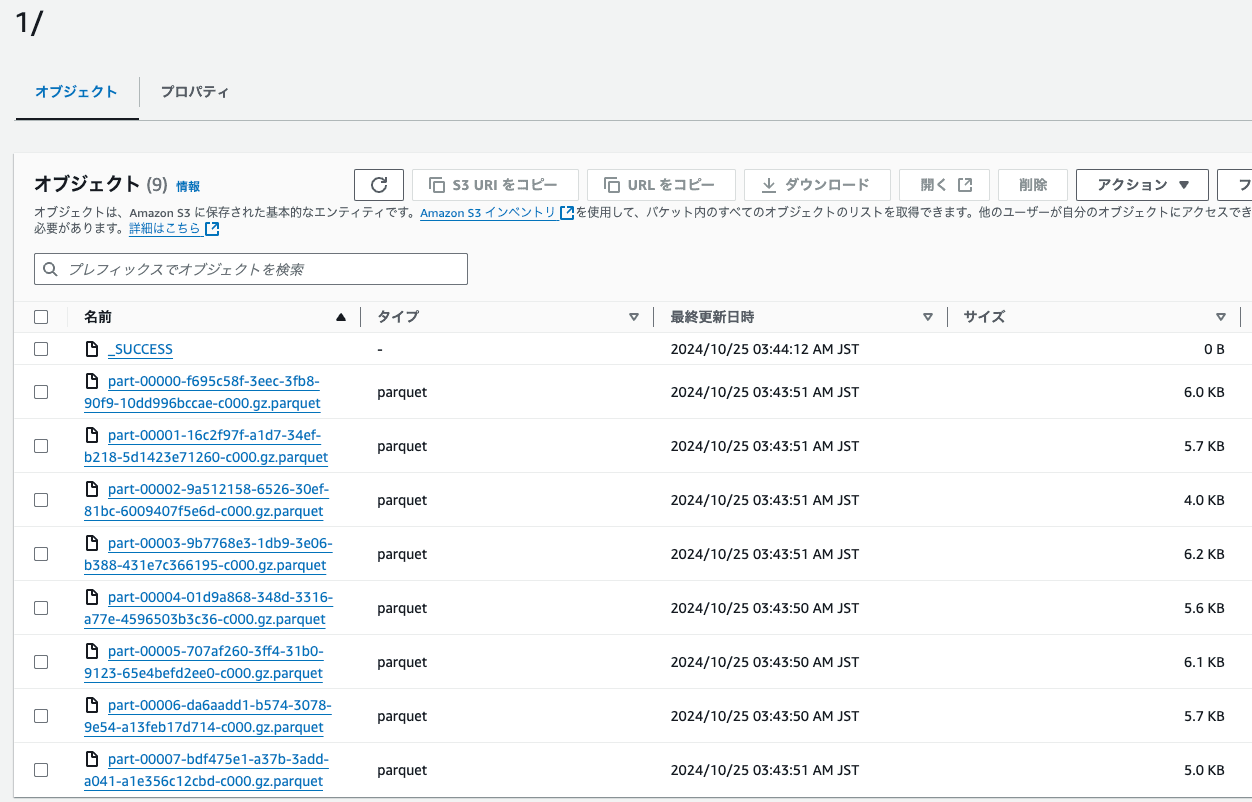
プレフィクス(export identifier)以下の具体的なファイルPath
エクスポートされたParquetの具体的なファイルPathは 公式ドキュメントの「DB クラスタースナップショットのエクスポートに関する考慮事項」 によると、2024年10月現在、下記の通りです
指定したプレフィクス/database_name/schema_name.table_name/batch_index/part-partition_index-random_uuid.gz.parquet
テーブル名 ( table_name ) のところを変えていけば、テーブル毎に取り込みが可能です。
バッチインデックスなども含まれているので、基本的には
指定したプレフィクス/database_name/schema_name.table_name/*.gz.parquet
での取り込みが良いかと思います。
**ちなみに、**先ほどの 公式ドキュメントの「DB クラスタースナップショットのエクスポートに関する考慮事項」 のページは MySQL / PostgreSQL の Parquet へのマッピングなども載っているので一度目を通すのをオススメします。
エクスポートに対しては料金が掛かる
当たり前といえば当たり前ですが、エクスポートのたびに 「スナップショットまたはクラスターエクスポートのコスト」のページ にある通りのコストがかかります。GB単位での課金です。
大きなDBに対して調子に乗ってKickしまくらないようにはしたほうがいいと思います。
まとめ
今回はAuroraからS3へのデータエクスポートの方法についてまとめてみました。
なかなかわかりやすいコードを書いた記事がなかったので、どなたかの参考になっていれば幸いです。
Amazon S3 への DB クラスターデータのエクスポート のページに
ライブの Amazon Aurora DB クラスターから Amazon S3 バケットにデータをエクスポートできます。エクスポートプロセスはバックグラウンドで実行されるため、アクティブな DB クラスターのパフォーマンスには影響しません。
とあるとおり、この方法の場合、AuroraがDBをクローンしてからデータを抽出し、エクスポートするので、アクティブなDBクラスターそのもの、つまり本番のシステム系には負荷をかけないで済むのもメリットです。
基本的にはAuroraのデータを分析に使いたい場合はこれがベストプラクティスだと考えています。
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 データ戦略チーム
アプリケーションからインフラ、ネットワーク、データエンジニアリングまで幅広い守備範囲が売り。最近はデータ基盤の構築まわりに力を入れて取り組む。 主な実績として、M-1グランプリ敗者復活戦投票システムのマルチクラウド化等。




