RAGを用いた人事Q&AアプリをGoogle Chatbotでリリースしました
概要
LLM-PJの中井です。
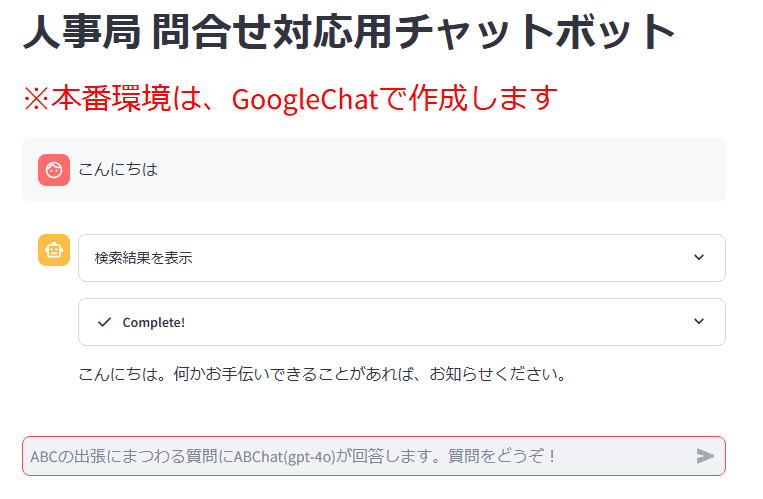
2024年12月2日、PoCを始めてから早1年以上、RAGを用いた人事Q&Aアプリ「人事局 社内アシスタント by ABChat」をリリースすることができましたので、ご紹介させていただきます。
「人事局 社内アシスタント by ABChat」とはなにか
社内情報である人事部の情報に回答できるチャットボットです。
ユーザからの質問をベクトルに変換し、Azure AI SearchでHybrid検索を実行。検索結果を元にLLM(AOAIのgpt-4o)が回答する仕組みです。
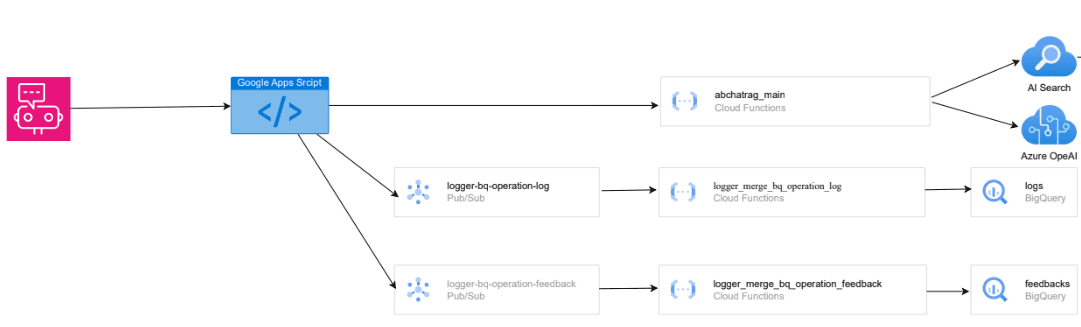
構成
構成は以下の通りです。
今回はTV社、HD社が本籍の社員にのみ閲覧させるため、それぞれの社が利用しているGoogle Workspaceの情報を簡単に利用する目的で、FrontにGoogle Apps Script(GAS)を利用しています。
セキュアにするため、Google Cloud FunctionsがGASのチャットボットからの呼び出しにしか回答しないよう実装したり、クラウド設定診断サービスを利用して設定を修正した上でリリースしました。
リリースするまでの流れ
PoC 2023/11-2024/3
1年以上前の2023年11月頃から、RAG / Grounding などと呼ばれていたものを実装すべく、PoCを行っておりました。
検証したものは、FAISS、Vertex AI Search、Kendora、Azure AI Searchなどでしたが、検証当時で、最も精度が高いと思われたものがAzure AI Searchでした。
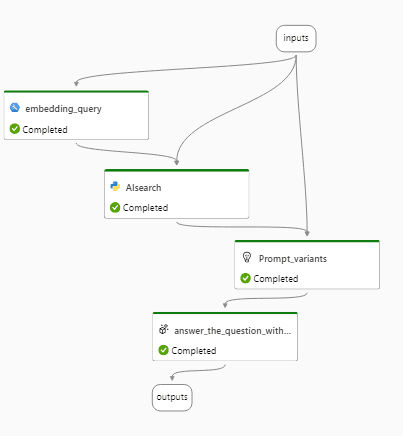
検証はAzure Prompt Flowを用いて実行していました。
Prompt Flowでは、あらかじめ用意したテストデータ(Q&Aのデータ)を元に、Qの内容を自動でRAGを用いたLLMで実行し、得られたAをテストデータに記載された正答と比較し、LLMを用いてスコアリングしました。
ただし、生データ(社内の規定など加工していないデータ)をそのまま利用したところ、かなり精度が低い状態でした。
- 生データでのAI Search(弊社の場合、1年以上前)
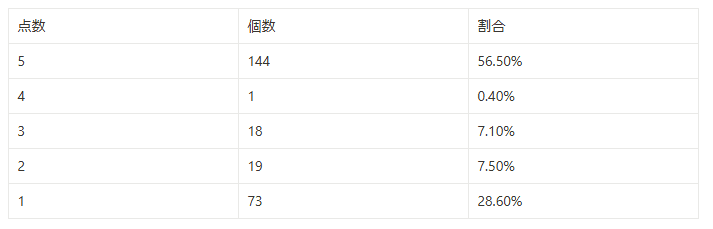
データの構造化が必要であることを痛感し、Softbank社のTASUKI Annotation 生成AI用データ構造化代行サービスを利用し、サンプルデータを構造化していただきました。
結果、以下の通り目標である「9割がスコア5」を達成し、満足のいく回答精度となりました。
- 構造化データでのAI Search(弊社の場合、2024年3月頃)

そのため、Azure AI Searchを用いてRAGを実装することが決定、リリースに向けて作業が始まりました。
リリースに向けて 2024/4-11
当初は我々ICTチームのマニュアルを元にRAGをお試しで実施しようとしていましたが、人事部の業務改善・効率化の一環で人事Q&Aに回答するChatbotを利用したいというお話があり、人事部の協力を得ながら進めていくことになりました。
PoCの知見を活かし、データ構造化を進めPrompt Flowによるスコアが「5」となる回答が9割を超えるようになりましたが、やはりリリースにはそれだけでは不足しており、致命的な間違いや言い回しの修正をその後実施しました。
Streamlitで作成した簡易なRAGチャット環境を用意し、人事メンバにも実際に触ってもらいながらデータを修正する作業を繰り返しました。
夏にリリースしたいという話も出ていたのですが、セキュリティ対策を施すためにお時間を頂戴し、先日、無事にリリースすることができました。
今後について
現在は人事の一部内容についてのみ回答できる状態ですが、今年度中にはデータ構造化の範囲を人事の全データに広げ、回答できるようにしたいと考えています。
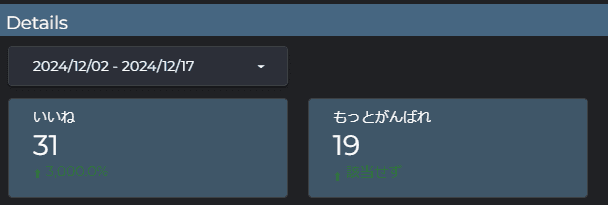
また、「人事局 社内アシスタント by ABChat」が回答した内容にユーザが「いいね」「もっとがんばれ」をアクションすることができます。
それらの情報はLooker Studioで可視化しており、データを修正してより回答精度を高めていく方針です。
まとめ
RAGを用いたQ&Aアプリ、やはりデータ構造化が一番大変でした。
GraphRAGなどもありますが、Geminiなどの長いContext Windowを持ったLLMが出てきている今であれば、Many-Shot In-Context Learning(May-Shot ICL)が選択肢の一つになるでしょうし、データ構造化もここまで大変ではなかったと思います。
一区切りついたら、今後は方式変更を検討したいところです。
(そう言っている間にGoogle WorkspaceのGeminiがもっと進化するかも!?)
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 ICTチーム
2008年入社、ICTチーム(情報システム・働き方改革)所属。 ネットワーク・セキュリティエンジニア。HD/TV/RD社の業務系NWやツール(GWS, IDaaS, etc)の担当。CSIRTメンバ。2023年のABChat導入などABCグループの生成AI導入も先導。 NWを中心とした全社IT設備統合PJも実施中。




