BigQuery ML で Gemini を利用して Google 検索によるグラウンディングを試してみた
BigQuery 内で Gemini を利用して Google 検索で精度を上げる
BigQuery でも 生成AI を使いたい
生成AIが世の中に当たり前になりつつある昨今ですが、普段からデータ分析を行っている方であれば、こういったことを考えたことはないでしょうか?
🤔BigQueryのテーブル内のデータを生成AIに渡して、新たなデータを生成できないのか??
なんと、それ BigQuery ML でできます!
今回はそんな BigQuery ML で Google の LLM である Gemini を利用して、新たなデータを生成する方法について書いてみようと思います。
BigQuery ML で Gemini を利用する方法
そもそも、BigQuery ML とは「BigQuery の AI と ML の概要」にもあるように、GoogleSQL クエリを利用して、MLモデルの作成と実行が簡単に行える機能で、最近では既存の LLM にアクセスして、文章の生成や翻訳などの AI タスクも簡単に行えるようになりました。
今回は、こちらの「ML.GENERATE_TEXT 関数を使用してテキストを生成する」を参考に BigQuery で実行されるクエリから Gemini を呼び出して AI タスクを実行させてみたいと思います。
簡単な設定方法は以下の通りです。
1.接続を作成して、サービスアカウントを取得する
まず、BigQuery のトップページ左上にある【+追加】をクリックします。
続いて、【外部データソースへの接続】をクリックします。
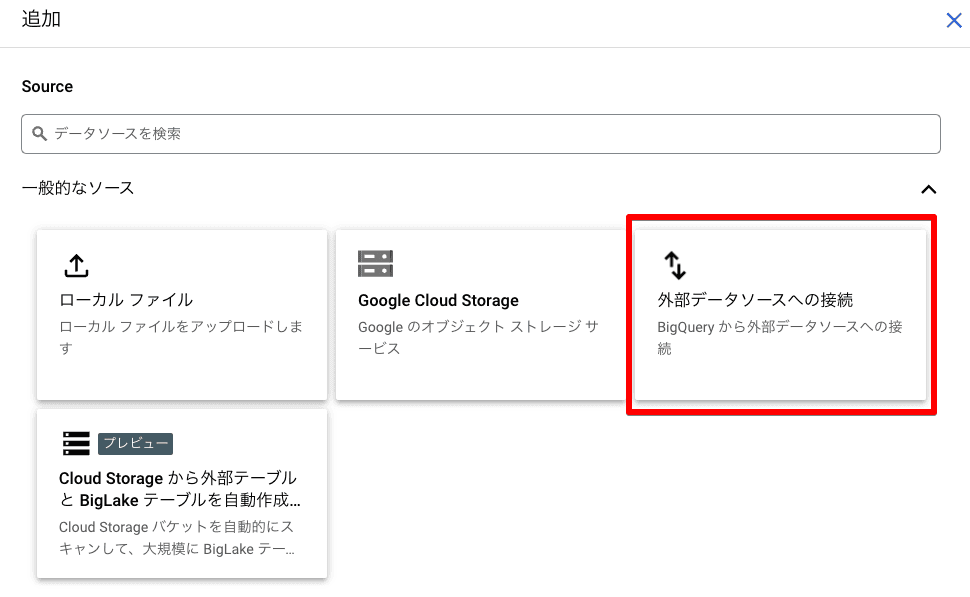
外部データソースの接続タイプとして【Vertex AI リモートモデル、リモート関数、BigLake(Cloud リソース)】を選択します。
その他、接続ID、リージョンも任意の値を入力・選択して、【接続を作成】をクリックします。

すると、以下のように外部接続内に先ほど作成した接続が作成されるので、そこに表示されているサービスアカウントIDをコピーします。
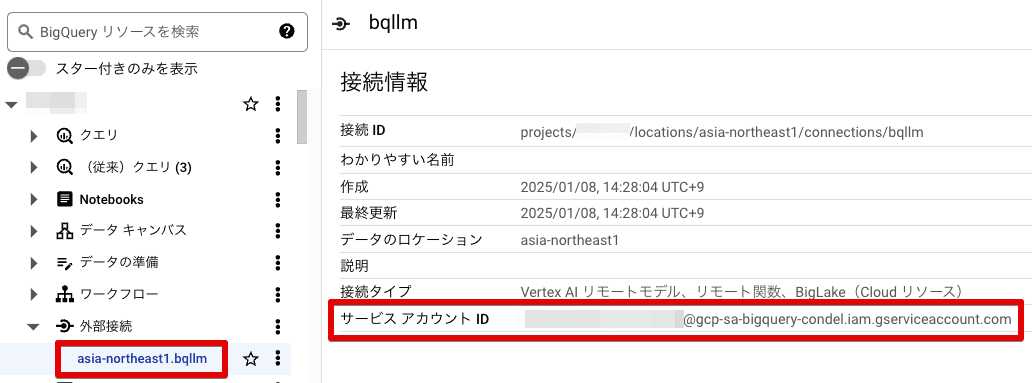
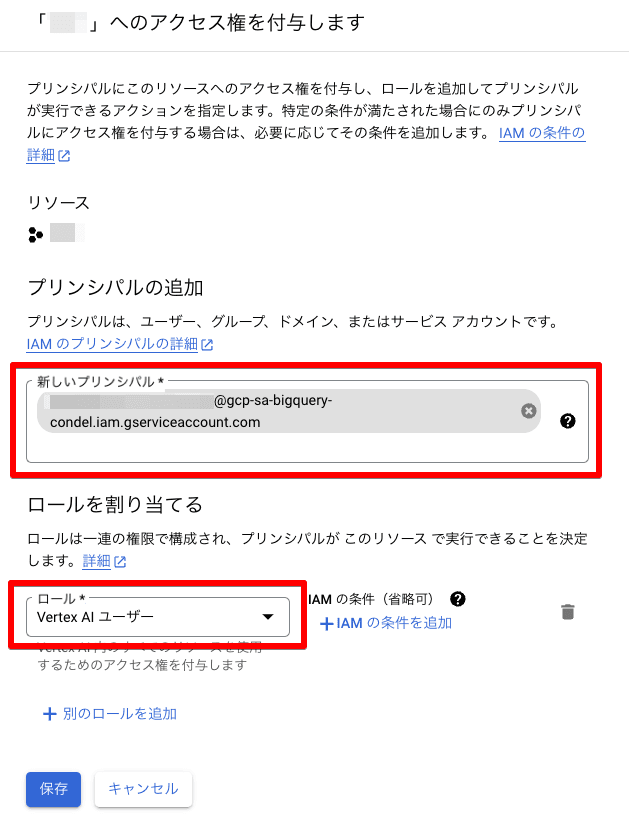
2.サービスアカウントにアクセス権を付与する
「IAM と管理」内で先程作成したサービスアカウントに【Vertex AI ユーザー】ロールを割り当てます。
3.BigQuery ML リモートモデルを作成する
以下の SQL を走らせることで、リモートモデルを作成します。
ちなみに、今回は gemini-1.5-flash-002 というモデルを利用します。
CREATE OR REPLACE MODEL
`[プロジェクト名].[データセット名].test_model`
REMOTE WITH CONNECTION `[接続ID]`
OPTIONS (ENDPOINT = 'gemini-1.5-flash-002');
なお、接続IDは以下の赤枠内の ID になります。
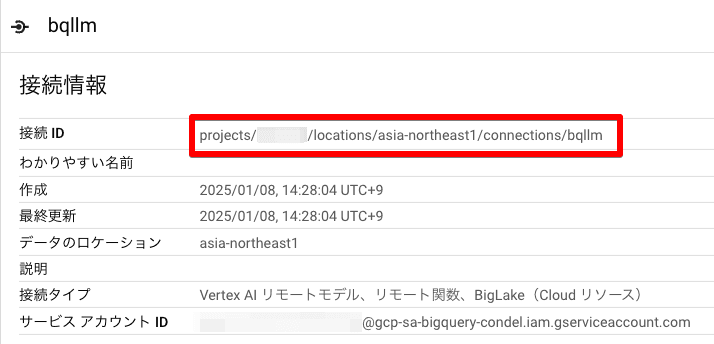
無事にモデルが作成されたら以下のように表示されるはずです。
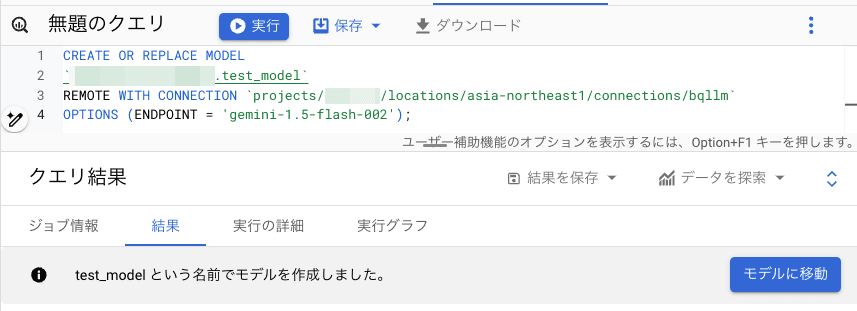
ここまでで外部接続を利用したリモートモデルが作成できました。
ここからは、実際に作成したモデルを利用して、既存のデータをもとに新たなデータを生成してみたいと思います。
Gemini を利用して新たなデータを生成してみる
今回は、「平仮名で書かれたテレビ番組名を正式名称に直したデータを生成する」というタスクを与えてみたいと思います。
まずは、適当なデータを用意します。
-- テーブル作成
CREATE OR REPLACE TABLE `[プロジェクト名].[データセット名].programs` (
program_name_kana STRING
);
-- データ挿入
INSERT INTO `[プロジェクト名].[データセット名].programs` (program_name_kana)
VALUES
('おはようあさひです'),
('なるみおかむらのすぎるTV'),
('あいせきしょくどう'),
('これよだんなんですけど'),
('やすとものいたってしんけんです'),
('たんていないとすくーぷ'),
('たびさらだ'),
('しんこんさんいらっしゃい'),
('ぽつんといっけんや'),
('かくづけちぇっく');
以下のようなテーブルが作成できました。

このテーブルのデータを利用して、以下のようなクエリでリモートモデルに対してプロンプトを投げてみます。
SELECT
REGEXP_EXTRACT(prompt, r'#対象の番組名\n(.*?)\n#出力方法') AS program_name_kana,
ml_generate_text_llm_result AS program_name_modified
FROM ML.GENERATE_TEXT(
MODEL `[プロジェクト名].[データセット名].test_model`,
(
SELECT CONCAT(
"#役割\n",
"あなたは日本のテレビ番組に詳しい専門家です。\n",
"#タスク\n",
"あなたの知識を使って、以下の平仮名で書かれた番組名を、正しい表記に直してください。\n",
"#対象の番組名\n",
program_name_kana, "\n",
"#出力方法\n",
"正しい表記の番組名のみを表示してください。\n"
) AS prompt
FROM `[プロジェクト名].[データセット名].programs`
),
STRUCT(0 AS temperature, 0 AS top_p, TRUE AS flatten_json_output)
)
MODEL 部分に先ほど作成したリモートモデル名を設定して、その後にプロンプトデータを提供するクエリを記述し、最後に各種パラメータを設定します。
ここでは、ランダムなレスポンスを少なくするために、temperature と top_p の値を0に設定しました。
各種パラメータの説明は「クエリのプロンプトを使用してテキストデータからテキストを生成する」に詳しく書いています。
上記のクエリの結果が以下になります。

割と精度良く変換できておりますが、「芸能人格付けチェック」「これ余談なんですけど・・・」辺りは誤った変換になっております。
では、次に Google 検索を用いたグラウンディングを行った場合に結果がどうなるか見てみようと思います。
Google 検索を用いたグラウンディングで精度を上げる
そもそも、グラウンディングとはモデルの出力を、検証可能な情報源に紐付ける仕組みで、ハルシネーションの削減に有効とされています。
今回は膨大な情報量を持つ Google 検索を利用して、より精度の高い出力を得ようということになります。
Google 検索を用いたグラウンディングを行うためのクエリが以下になります。
一見、先程のクエリと同じに見えますが、TRUE AS ground_with_google_search というパラメータが追加されており、この一文を追加するだけで簡単に Google 検索の情報を利用することができます。
SELECT
REGEXP_EXTRACT(prompt, r'#対象の番組名\n(.*?)\n#出力方法') AS program_name_kana,
ml_generate_text_llm_result AS program_name_modified
FROM ML.GENERATE_TEXT(
MODEL `[プロジェクト名].[データセット名].test_model`,
(
SELECT CONCAT(
"#役割\n",
"あなたは日本のテレビ番組に詳しい専門家です。\n",
"#タスク\n",
"あなたの知識を使って、以下の平仮名で書かれた番組名を、正しい表記に直してください。\n",
"#対象の番組名\n",
program_name_kana, "\n",
"#出力方法\n",
"正しい表記の番組名のみを表示してください。\n"
) AS prompt
FROM `[プロジェクト名].[データセット名].programs`
),
STRUCT(0 AS temperature, 0 AS top_p, TRUE AS flatten_json_output, TRUE AS ground_with_google_search)
)
こちらが、Google 検索によるグラウンディングを行った場合の結果になります。

「これ余談なんですけど・・・」が変換されずに平仮名のままですが、それ以外は完璧です!
特に注目すべきなのが、「芸能人格付けチェック」や「朝だ!生です旅サラダ」といった平仮名表記では不完全だった番組名を正式名称に直してくれています。
このように、Google 検索によるグラウンディングを行うことで、かなり精度の高い結果を得ることができました。
まとめ
BigQuery ML にてリモートモデルとして Gemini を利用して、AI タスクを実行してみました。
また、Google 検索によるグラウンディングを用いることで、より精度の高い結果が得られることを確認できました。
特に正解が決まっているタスクについては、インターネットの情報を利用できるということもあり、非常に相性の良い機能かと思います。
最近では Gemini 2.0 といった新たなモデルも発表されており、今年も、生成 AI の進歩には注目しつつ、どのようにして新たな価値を創出できるか常に考えていけるようにしたいですね!
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 データ戦略チーム
グループ全体の統合的なデータ基盤の構築・データ分析の支援に従事している。 動画配信・テレビの視聴データ分析等で身につけた幅広い知識を活かして日々奮闘中!




