Supabase の DB と BigQuery を Datastream を使って連携させる
Supabase と BigQuery の Datastream によるデータ連携時の設定ポイント
Supabase のデータを BigQuery で使う
特に少人数組織などで、とりあえずサクッとアプリを作るに際しては BaaS (Backend as a Service) の助けを借りることは必至かと思います。(余談ですが、最近は BaaS と検索すると Banking as a Service のほうが多く出てきたりとかして、FinTech界隈の盛り上がりを感じます)
恐らく多くの人の頭に最初に浮かぶのは Firebase とか、 Amplify かなと思うのですが、個人的に最近よく使っているのは、自ら 「The Open Source Firebase Alternative」 と打ち出している BaaS の Supabase です。
それらの比較の話もしていきたいところですが、今回は Supabase 内のDB(PostgreSQL)と BigQuery をマネージドサービスの Datastream によって連携させるときの話です。
結局分析となると、Supabase の内容をBigQueryのような分析基盤にコピーしたくなると思いますので、そういったユースケースで使える話かと思います。
Datastream について
データの複製・同期といったシステムは、常時稼働が求められるシチュエーションが多いかと思います。
ちゃんとしたデータマネジメント部隊が整っていれば、Cloud Composer(Airflow)やらなんやらでなにがしか自分たちで組み上げることも考えられますが、Supabaseを使っている組織の場合メンテナスコストはとにかく下げたいということのほうが多いのではないでしょうか。
そうなってくると結局はやはりフルマネージドなサービスを使うほかありません。
そこで、今回使用するのは Google Cloud の Datastream です。
Datastream は、PostgreSQL だけでなく、My SQLやOracle、SQL Serverとも連携可能で、CDC(変更データキャプチャ)を使っての連携の場合はリアルタイム同期を行ってくれます。
それでいて料金は「データ処理量に基づく費用」と単純明快です。
今回はこの Datastream を用いて Supabase の DB のデータを BigQuery に連携してみたときのポイントをまとめます。
Supabase DB と Datastream の連携設定時のポイント
基本は 公式ドキュメント「セルフマネージド PostgreSQL データベースを構成する」 に従えばOKですが、いくつかSupabaseの場合はどうなる?なポイントがありますのでそこをまとめていきます。
必要要件
まず残念なお知らせですが、
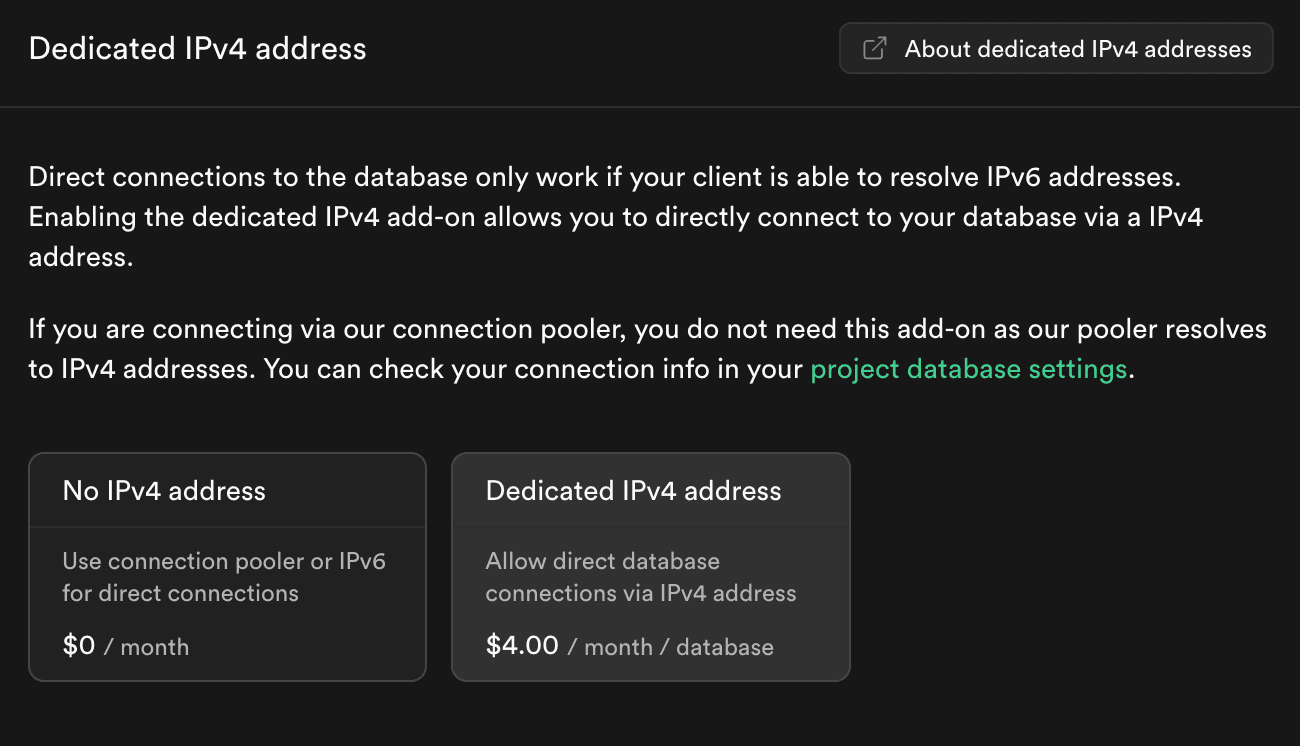
2025/02現在では DatastreamがIPv6での接続に対応していないため、Dedicated IPv4 address のAdd-onへの課金が必要、Add-on 単品での課金は不可能かと思いますので Supabase のプロジェクト自体への課金も必要となります。
ちなみに Add-on は2025/02現在 $4/month/DB です。これが最初のハマりどころです。
ただ、BigQuery連携を考えるレベルのサービスであれば課金はしてあるでしょうから、そこまで痛手ではないと思います。
本当に繋がるのかどうか確かめたい…という方向けには本記事が人柱代わりになっていれば幸いです。
Supabase DB 側設定
まずは Supabase 側で必要な設定です。公式ドキュメントにある 論理レプリケーションの有効化処理は不要 です。(すでに有効なため)
論理レプリケーションのためには Publication とそのためのスロットを作成する必要がありますので、それらを bq_pub および bq_slot と名付けて作成します。(名前はもちろん自由です)
CREATE PUBLICATION bq_pub FOR ALL TABLES;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('bq_slot', 'pgoutput');
また、ユーザーを作成します。ここでは仮に bq_user とします。(パスワードは任意)
CREATE USER bq_user WITH ENCRYPTED PASSWORD '********';
このユーザーに各種権限の付与を行います。
ALTER ROLE bq_user WITH REPLICATION;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO bq_user;
GRANT USAGE ON SCHEMA public TO bq_user;
ALTER DEFAULT PRIVILEGES IN SCHEMA public
GRANT SELECT ON TABLES TO bq_user;
ここではスキーマpublic 内の全てのテーブルについての許可を出していますが、個人情報データ等あればテーブルの権限を絞るなどしたほうが良いでしょうし、実際はもう少し変更が必要になると思います。
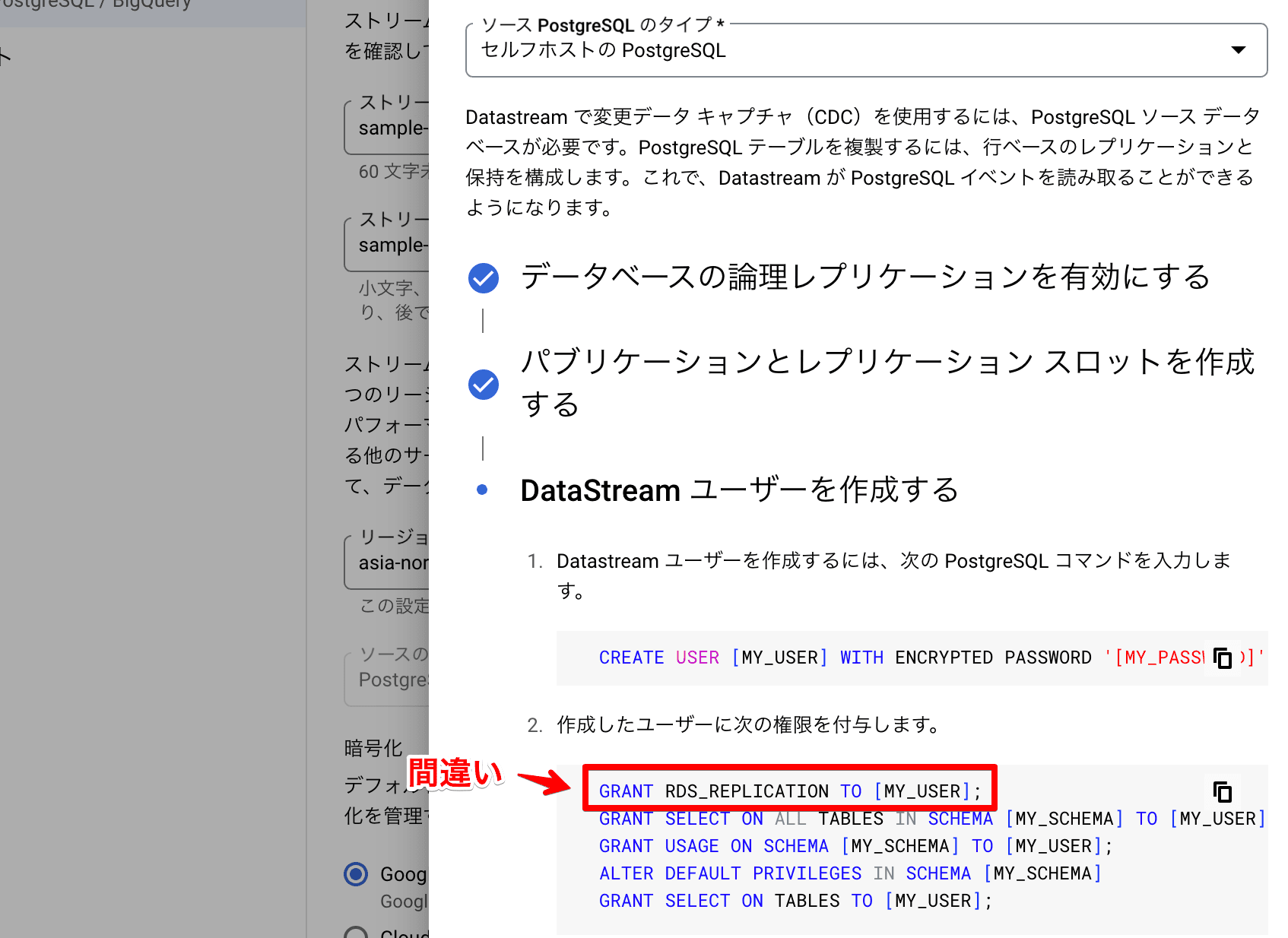
ここでプチハマりポイントとしては、
先述の公式ドキュメントの記述は正しいのですが、2025/02 現在、 Datastreamの設定画面のサンプルは間違っているという罠がありますので注意が必要です。(セルフホストではなくdehanakuRDSの場合の設定が記述されている; たぶんすぐ修正されるでしょう・・)
正確には ALTER ROLE での指定となります。
そして、これは大きめのハマりポイントですが
行レベルセキュリティ(RLS)が効いている場合はこのユーザーに下記クエリでRLSをバイパスさせるなどして許可を通しておく必要があります。
ALTER USER bq_user BYPASSRLS;
RLSを適用していないテーブルのほうが少ないでしょうから、ここは特に注意が必要です。
RLS適用なしのテーブルと適用ありのテーブルが混ざっている場合、RLS適用なしのテーブルだけは複製できるから設定は間違っていなさそうなのになぜかデータが複製されないテーブルも存在する…みたいなことになって混乱します。 (というか、しました)
ちなみにこれは、公式ドキュメント「よくある質問」の「PostgreSQL ソースの動作と制限事項」の箇所に記載があります。また、 先述の公式ドキュメント内の「基地の制限事項」の箇所 も必読です。
そして先述の通り、 IPv4 のAdd-onの有効化も忘れずに行ってください。
ここまでできたら Supabase 側で実施することはありませんので、
Google Cloud 側にて Datastream APIを有効化して、ストリームの作成作業に移ります。
「始める」

ここは適当にストリーム名を定めて、ソースタイプ「PostgreSQL」 宛先「BigQuery」を指定するだけです。
ちなみにこの項目内に先ほどの間違った手順解説が含まれていますがスキップでOKです。
ソースの定義とテスト
ここでソース接続プロファイルを作成します。
接続プロファイルの設定もハマりポイントです。
Supabase への接続に際しては、2つの接続先方法がありますが、今回 「接続プーリング」による接続は使用できません。
具体的には aws-0-ap-northeast1.pooler.supabase.com のポート 6543 へ
bq_user.[SupabaseのプロジェクトID] をユーザー名として繋ぎに行くような形はNGです。
具体的には下記のように設定すればOKです。
db.[プロジェクトID].supabase.co の 5432 に先ほど Supabase 側で作成したユーザー名とパスワード(例では bq_user )でデータベース postgres に繋ぐ形をとればOKです。
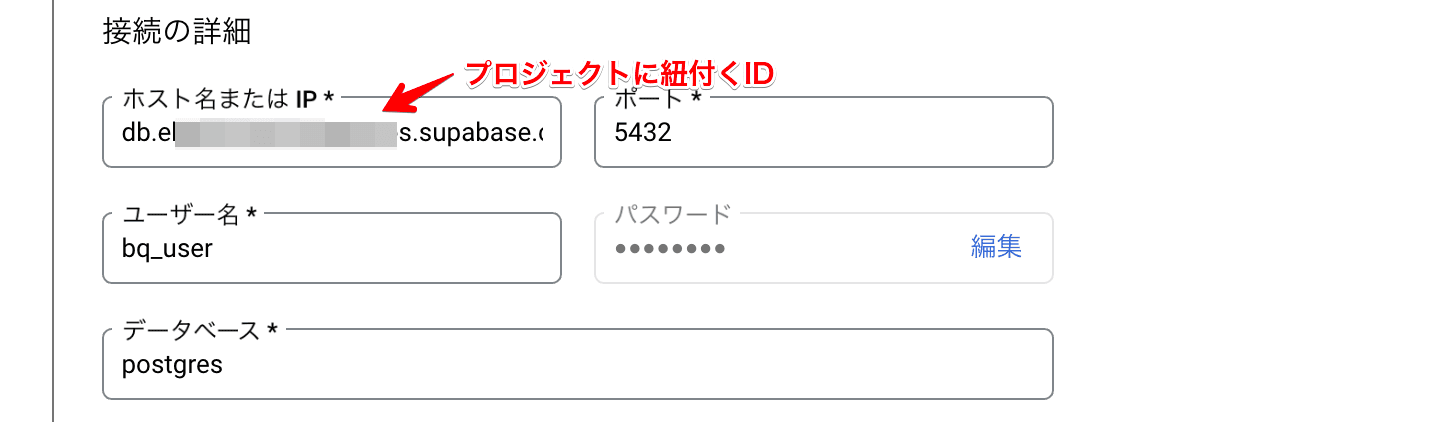
ちなみにプロジェクトIDはダッシュボードのアドレス等で確認可能です。

接続方法としては IP許可リストで問題無いかと思いますが状況に応じて変更すると良いでしょう。
これで接続プロファイルをテストすれば、「テスト成功」となるはずです。
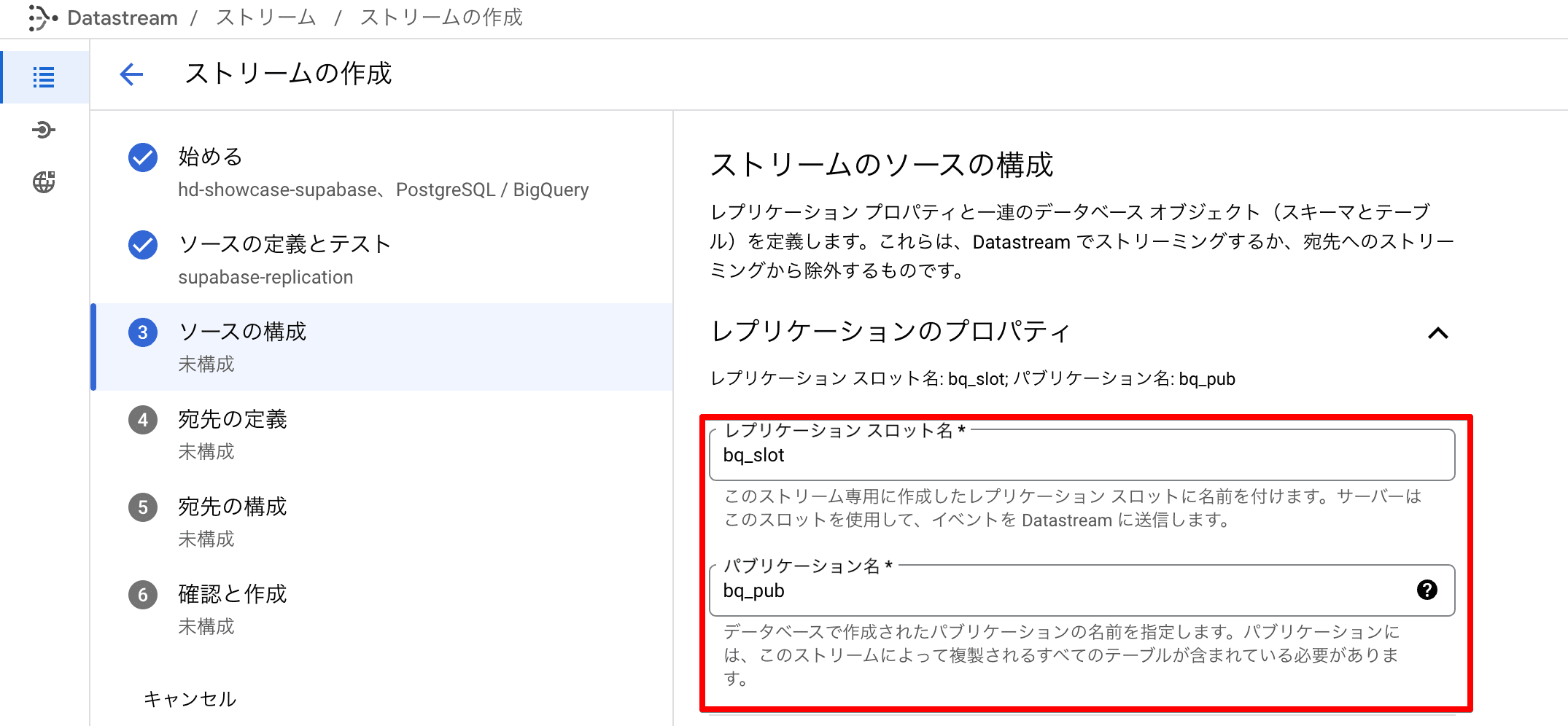
ソースの構成
ここは先ほど作成したPublicationおよびスロットを指定します。 (サンプルでは bq_slot と bq_pub としていました)
宛先の定義・構成
「宛先の定義」はBigQueryの場合特段詰まることはないと思いますが
「宛先の構成」において、 「スキーマ グループ化」の選択肢が現れます。
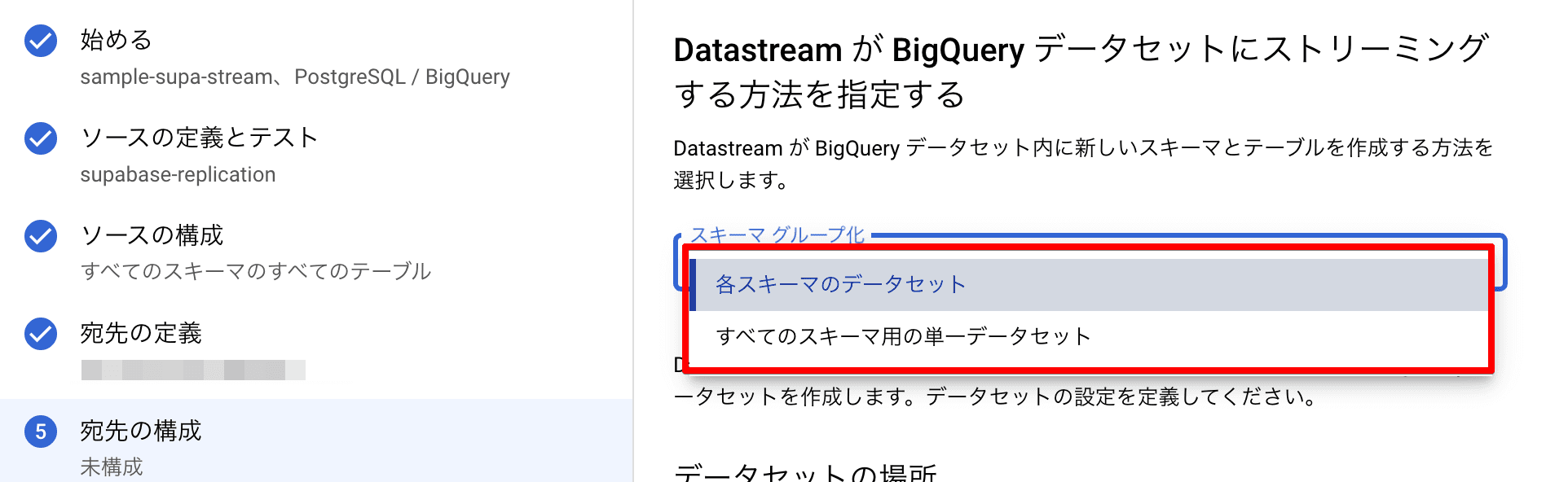
これらの説明としては公式ドキュメント「BigQueryの宛先を構成する」のページにあるとおり、下記の通りです
- 各スキーマのデータセット
- Supabase側のスキーマごとにBigQueryのデータセットを自動作成(Supabaseの
publicというスキーマを複製する際、BigQuery側にpublicというデータセットが作られる)
- Supabase側のスキーマごとにBigQueryのデータセットを自動作成(Supabaseの
- すべてのスキーマ用の単一データセット
- BigQueryの 一つのデータセット(こちらで指定可能) に
[スキーマ名]_[テーブル名]の形でテーブルが作られる
- BigQueryの 一つのデータセット(こちらで指定可能) に
上記の通り、「すべてのスキーマ用の単一データセット」を選択すると、データセットが指定できます。
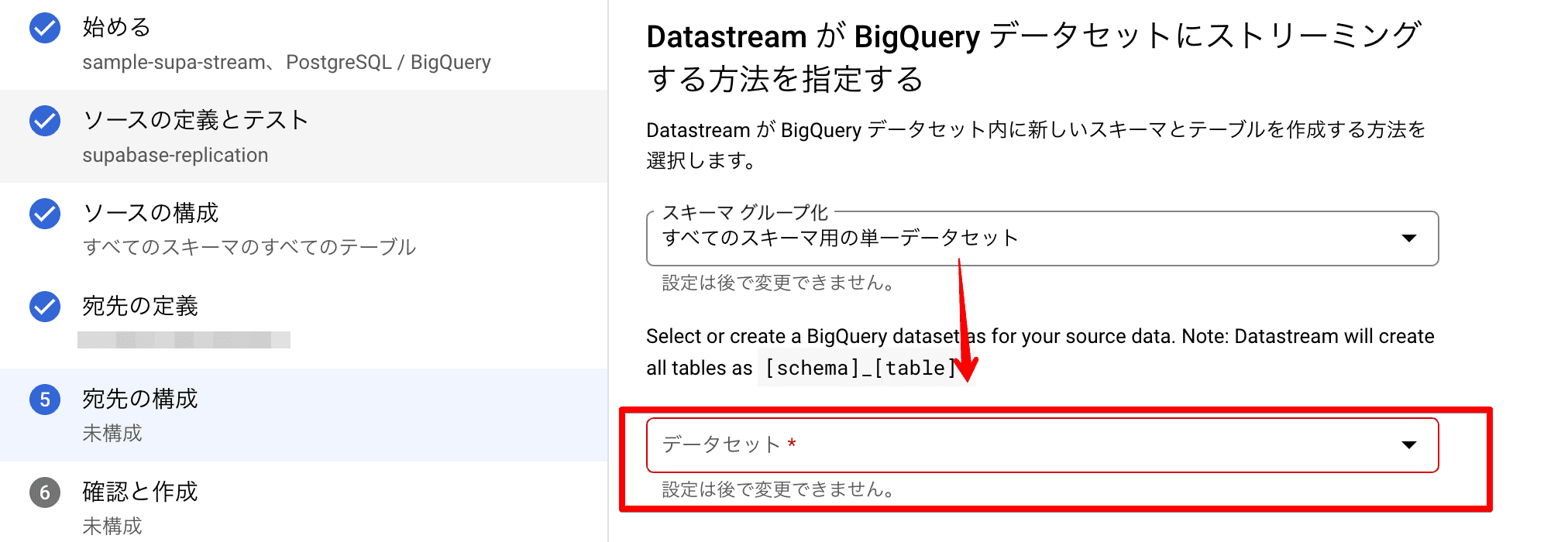
Supabase と同期を取るためだけのBigQueryプロジェクトであれば、「各スキーマのデータセット」でも問題ないかと思いますが
既存のBigQueryに対して同期する場合などを考えると、「すべてのスキーマ用の単一データセット」のほうが使い勝手が良いように思います。
作成・バックフィル
以上で確認して作成・実行するとバックフィルによって、同期が取れ始めると思います。
※ 当然ながらDBのデータがすでに大きいと時間もかかりますしデータ処理量に応じた課金も走ります
バックフィルが完了したら、Datastream 側の表示で「完了」となります。
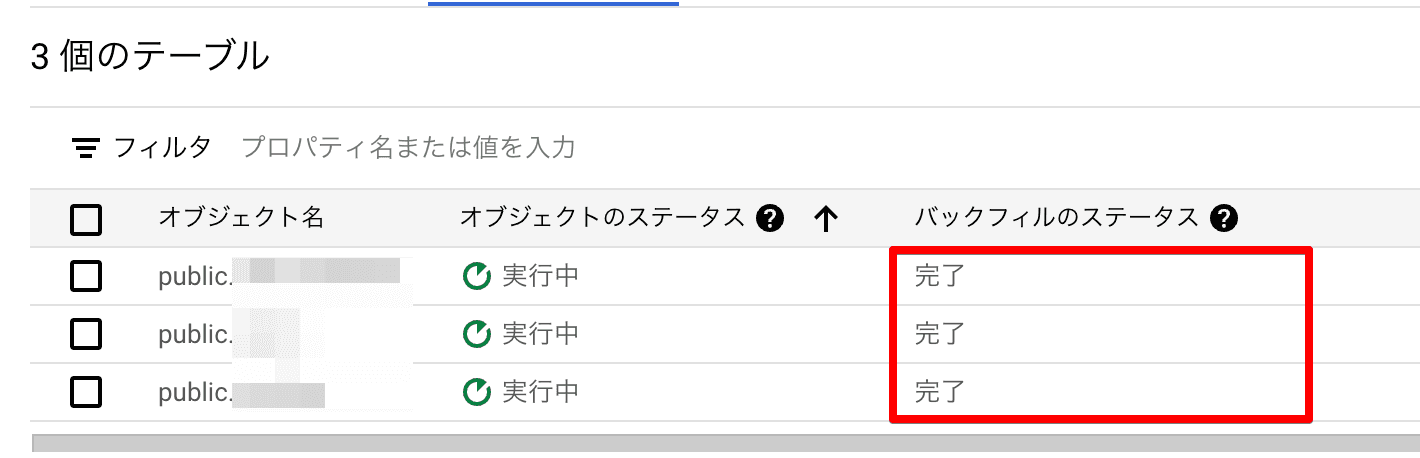
BigQuery でもクエリを走らせるなどで確認が取れるはずですが、
最初はストリーミングバッファに格納されますので、特にデータが小さい場合はクエリしてもしばらくは0件となるかもしれません。
ちゃんと来ているか不安…という方は BigQueryのテーブル詳細内の最下部にある「ストリーミングバッファ」を確認すると良いかと思います。

まとめ
今回は フルマネージドなサービス Datastream による Supabase と BigQuery の連携における設定項目のポイントについてまとめました。
簡易分析はSupabase内で完結させることも可能ですが、アプリケーションのデータを用いた分析を行う際は BigQuery の力を借りたほうがやはり快適ですね。
Looker Studioとの連携なども考えられますし、特に GA4 の BigQuery へ Export したイベントデータなどは連携によってより詳細な分析が可能になるのではないでしょうか。
すんなりいくかと思いきやハマりポイントも多かったので、本記事がどなたかの参考になっていれば幸いです。
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 データ戦略チーム
アプリケーションからインフラ、ネットワーク、データエンジニアリングまで幅広い守備範囲が売り。最近はデータ基盤の構築まわりに力を入れて取り組む。 主な実績として、M-1グランプリ敗者復活戦投票システムのマルチクラウド化等。




