BigQuery と Looker のソート順の違いから知る JavaScript の 日本語環境でのソートの罠
日本語環境で JavaScript のソートが想定通り機能しないタイミング
Looker のソート順が BigQuery と比べておかしい?
夏に聞きたい話といえば、やはり怪談でしょう。
エンジニアリング業務に携わると、日常的に怪談に出くわしますよね。今日はそんな中から一つ紹介できればと思います。
弊社では可視化において Looker を活用していますが、ある日突然こんな問い合わせをいただきました。
昇順に並べ替えても、「2025年度上期」が「2025年度下期」より下に来るのですが…
並び順の指定を間違えて操作しているだけなのでは…なんて思いながら、とりあえずテスト用のExploreを立ち上げて確認をします。
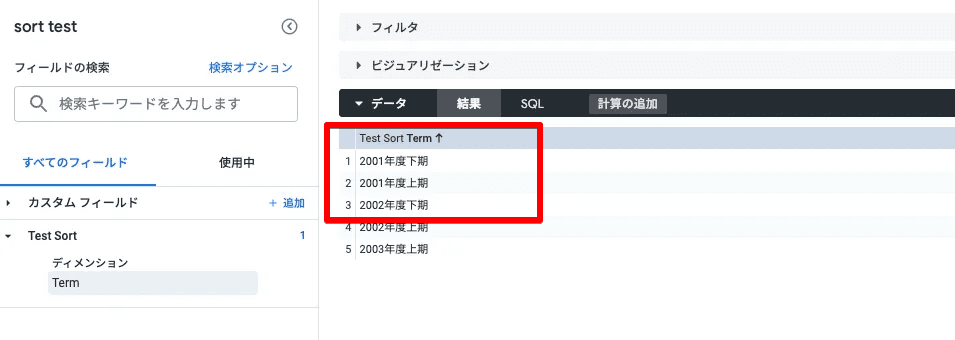
たしかに並べ替えた状態で 2001年度下期、2001年度上期、2002年度下期… と並んでいます。
BigQuery で確認します。
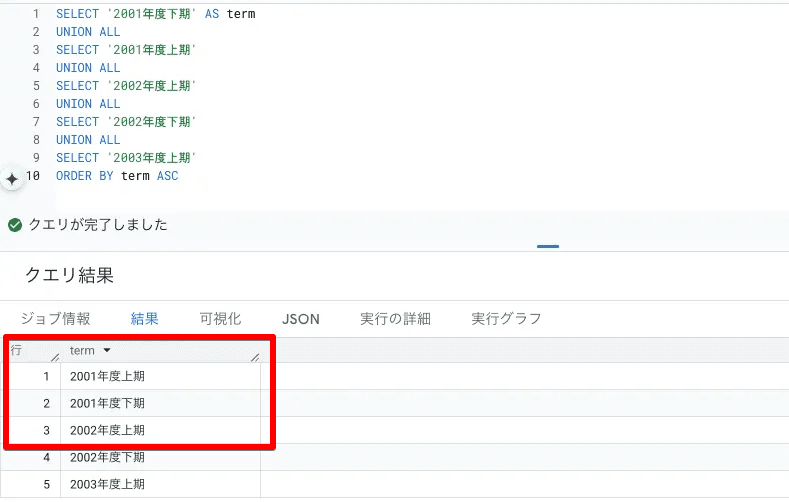
打って変わってこちらは想定通り、 上期 → 下期の順で 並んでいます。
はい、怪談認定です。
ちなみにこれは2025/08/27現在、下記のLookMLでどなたでも確認出来る内容ですので、Looker の環境がある方で、涼しくなりたい方はどうぞ
view: test_sort {
derived_table: {
sql: SELECT '2001年度下期' AS term
UNION ALL
SELECT '2001年度上期'
UNION ALL
SELECT '2002年度上期'
UNION ALL
SELECT '2002年度下期'
UNION ALL
SELECT '2003年度上期' ;;
}
dimension: term {
type: string
sql: ${TABLE}.term ;;
}
}
explore: test_sort {
label: "sort test"
}
原因を究明する
なんでこうなったのかをちゃんと検証してみます。
原因の推測と検証
まず、大前提として、BigQueryの昇順・降順のソートは先ほどの画像のとおり正しいです。
LookerはBigQueryからデータを取り寄せていますが、並び替えについては違った順番になっていることから、Looker自体で行っていることがわかります。
そしてその後LookerのJSを適当に見ていくと、 localeCompare でソートしていることがわかりました。
結論から言うと、これが罠です。
localeCompare について
ここからはLooker云々というより、JavaScriptの話です。
localeCompare という関数について説明します。
JavaScriptのlocaleCompareメソッドは、文字列を比較するためのメソッドで、文字列の並び順を決定する際に使われます。このメソッドは言語に依存した文字列比較を行うために設計されています。
基本的な使い方は次のようになります。
const result = string1.localeCompare(string2);
このメソッドは次のような値を返します。
-1:string1がstring2より前に来る場合0:string1がstring2と等しい場合1:string1がstring2より後に来る場合
ただし、ここでポイントなのは、 特に引数で設定していない場合、ユーザーの環境のロケール設定に依存して比較を行う ということです。
localeCompareの挙動
というわけで、この localeCompare の挙動を確認していきます。
適当に、Node.js などを立ち上げて簡単に確認が取れると思います。
まず、下記。
"1".localeCompare("3")
この場合、 1 のほうが 3 より小さいので、 -1 が正解です。
ついに 上期 と 下期 を比較できるタイミングが来ました。
やってみましょう。
"2021年度上期".localeCompare("2021年度下期")
2021年度上期 は 2021年度下期 より前に来てほしいので、 -1 が出てほしいわけですが…
Node.js で実行してみます。

はい。 下期 が 上期 より前に来ています。
しかし、ここからがさらなる怪談です。適当にUSリージョンにでも立てたインスタンスでも試してみます。

先ほどと結果が異なり、理想的な並び順となっています。
なぜこのような挙動になるか
本来的には、こういった文字列の並べ替えは Unicode 順で行われると思います。
今回で言うと、
- "上" (U+4E0A)
- "下" (U+4E0B)
となっていますので、 上が下より先に来るのが自然です
しかし、どうも正確なドキュメントを見つけることが出来なかったのですが…
localeCompare について、日本語環境では、漢字が音読みベースで並べ替えられるようなのです。
そうすると、 上はジョウ、下はゲあるいはカ…となり、いずれにせよ、下が上より先に来ているのではないかと推測しています。
ちなみに日本語環境でも、 < 演算子による比較を行った際は想定通りの(Unicodeベースの)結果が返ります

これが、ソート時に localeCompare を使うか、 sort を使うかによる差を生み出しているということになります。
ちなみに、 localeCompare はドキュメントを参照すると locales を指定できるので、ここで en を指定してしまえば、音読みによるソートは行われなくなり、今回でいう理想の並び方である、Unicode順になるようです。

味わい深いですね。
日本語の並び順になっていたほうがいいこともあるかとは思うので、もし利用する際はこのあたりの仕様を理解している必要がありそうです。
まとめ
今回は Looker と BigQuery の挙動差に端を発して気付いた、JavaScript のソートに関する挙動についての話でした。
どんな怪談も、仕組みが分かればそれはもう怪談ではなくなる!ということで、怪談ゼロの世界を目指して知識を拡げていきたいですね。
皆さんの暑さが少しでも和らいでいれば幸いです。
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 データ戦略チーム
アプリケーションからインフラ、ネットワーク、データエンジニアリングまで幅広い守備範囲が売り。最近はデータ基盤の構築まわりに力を入れて取り組む。 主な実績として、M-1グランプリ敗者復活戦投票システムのマルチクラウド化等。




