BigQuery での ML.GENERATE_TEXT から AI.GENERATE への移行検証
BigQuery から Gemini を叩く AI.GENERATE 関数の検証
BigQuery と AI の活用
BigQuery である程度データ基盤を構築する中で、便利に使えるものの一つに BigQuery ML というのがあります。
端的に言うと、BigQueryからそのまま機械学習系の機能やVertex AI系の機能を呼び出せるというものです。
今回はその中でも ML.GENERATE_TEXTというテキスト生成系の関数についての話です。
Google Cloud Next ‘25 にて発表された AI.GENERATE という新しい関数でどのように置き換えられるかについて検証した結果を扱います。(まだプレビュー版の関数となります)
ML.GENERATE_TEXT 関数
まず、従来より提供されていたテキスト生成系の関数である、 ML.GENERATE_TEXT 関数の話からです。
公式ドキュメントとしては「ML.GENERATE_TEXT 関数を使用してテキストを生成する」のページが該当します。
各種APIを有効にしてから、まず最初にコネクションを作ってからモデルを作成し:
CREATE OR REPLACE MODEL
`PROJECT_ID.DATASET_ID.MODEL_NAME`
REMOTE WITH CONNECTION {DEFAULT | `PROJECT_ID.REGION.CONNECTION_ID`}
OPTIONS (ENDPOINT = 'https://ENDPOINT_REGION-aiplatform.googleapis.com/v1/projects/ENDPOINT_PROJECT_ID/locations/ENDPOINT_REGION/endpoints/ENDPOINT_ID');
この作成したモデルを使用して呼び出します。
検証のため、とりあえず適当にデータセットを作ります。
CREATE OR REPLACE TABLE
`{{PROJECT_ID}}.{{DATASET_NAME}}.test_data_for_llm` AS
SELECT
1 AS id,
'BigQuery MLを使ってLLMモデルでテキストを生成するにはどうすればいいですか?' AS title
UNION ALL
SELECT
2 AS id,
'Pythonでデータフレームの重複行を削除する方法を教えてください。' AS title
UNION ALL
SELECT
3 AS id,
'Google Cloud Functionsをデプロイする際の手順は?' AS title

ML.GENERATE_TEXT 関数を利用してこれらに回答してもらいます。
SELECT
title,
*
FROM
ML.GENERATE_TEXT(
MODEL `{{PROJECT_ID}}.{{DATASET_NAME}}.llm_model`,
(
SELECT
title,
CONCAT('この質問に答えてください。質問:', title) AS prompt
FROM
g
),
STRUCT(
0.2 AS temperature,
1000 AS max_output_tokens,
TRUE AS flatten_json_output
)
)
すると、以下のような実行結果が得られます。
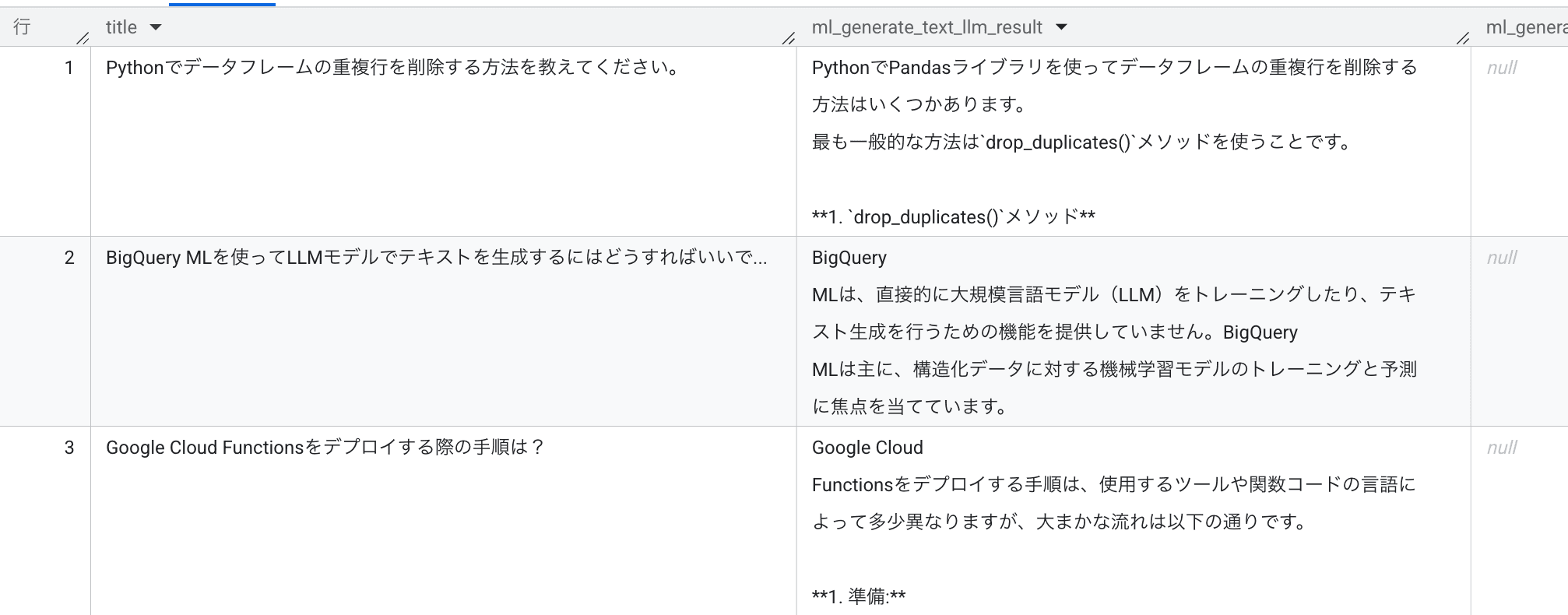
こういった例を見るだけだと今一つピンと来ないところもあるかもしれませんが、
データセット内のデータに対してまとめてAIにプロンプトを投げられるので、
- データ形式や長さが揃っていないようなデータ(例えばブログ記事本体など)に対してまとめて形式や書式の統一を行う
- データにカテゴリが付与されていないデータに対してカテゴリを振り分けて貰う
など、 新時代的な(?)前処理 を行うことができます。
今回この記事では扱いませんが、ML.GENERATE_EMBEDDING 関数を用いればエンベディングも作れますので、実際この組みあわせはよく使います(「ML.GENERATE_EMBEDDING 関数を使用してテキスト エンベディングを生成する」の記事 が参考になると思います)
また、使用するモデルはGeminiの他にもClaudeなど外部リソースも選択可能となっています。
ML.GENERATE_TEXT 関数の課題
これだけ聞くとめちゃくちゃ便利そうで良い感じなのですが、この関数の課題として、レスポンスが null となることがあります。(使用するモデルを Gemini 2.5 Flash にすると特に顕著です)
先ほどの例は Gemini 1.5 Flash を利用して作成していたのですが、Gemini 2.5 Flash に切り替えると…
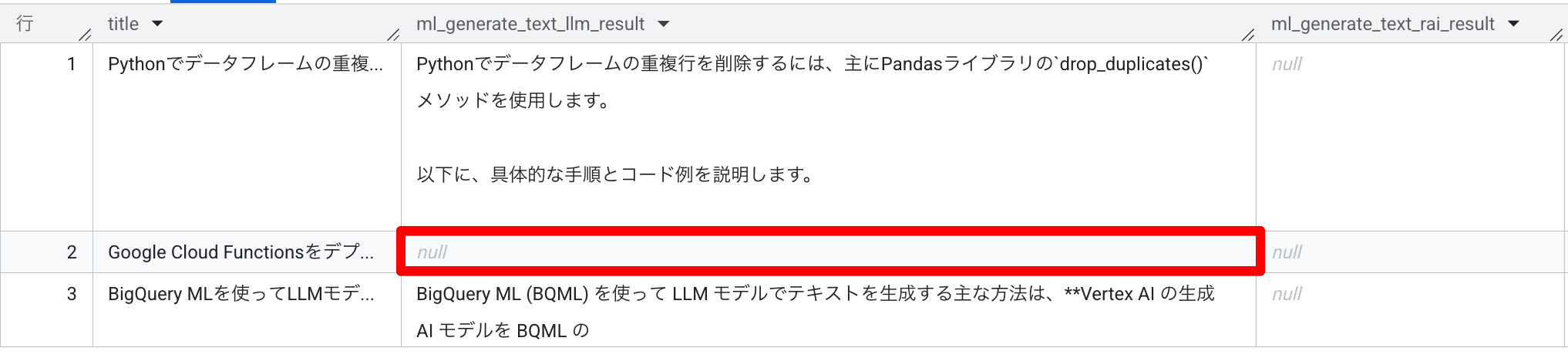
このように、 null が出てくる例が発生します。 temperature を上げつつリトライしたり、プロンプトチューニングで多少はどうにかなるのですが、 null が混ざってくる可能性が残ってしまうのはちょっと活用を見据えると難しいところです。(調べると色々な方が格闘している様子が見て取れると思います)
Gemini 1.5 Flash は割と安定していたのであまり気にせず使っていたのですが、いよいよ2週間後の 2025/09/24 にGemini 1.5 Flash が廃止されるということで気にしないといけなくなってしまいました。
Gemini 2.5 Flash Lite というさらに軽量なものもありますのでそちらなら null の割合を抑えられるのではないかと思ったりしますが、なんせデータセットが東京にあると東京のモデルしか使えず、基本的にGeminiはUSとヨーロッパにモデルが展開されているのですよね…
なので、必然的に東京リージョンにデータを集めていると東京で使える Gemini 2.5 Flash を使うことになるかと思います。
AI.GENERATE 関数を使う
そこで検証してみたのは、 AI.GENERATE 関数です。プレビュー版の出来たての関数です。
公式ドキュメントはこちら:「The AI.GENERATE function」
この AI.GENERATE でも同様に Gemini を呼び出せますが、いくつか違いがあります。
- モデルを作成する必要は無く、コネクションをそのまま指定する
- モデルごとに特有のパラメータを指定可能
- 出力のスキーマを指定可能
といったところです。
モデルのパラメータを指定して AI.GENERATE 関数を叩く
先ほどの質問データセットに答えて貰う処理を書き換えてみると、以下のようになります。
SELECT
title,
AI.GENERATE(
prompt => CONCAT('この質問に答えてください。質問:', title),
connection_id => '{{PROJECT_ID}}.{{DATASET_NAME}}.llm_connection',
endpoint => 'gemini-2.5-flash',
model_params => JSON '''
{
"generation_config": {
"temperature": 0.1,
"max_output_tokens": 1024,
"thinking_config": {"thinking_budget": 0}
}
}
'''
)
FROM
`{{PROJECT_ID}}.{{DATASET_NAME}}.test_data_for_llm`
このように、SELECT文の中に直接記述できるようになっているのも可読性の面では良いように思います。
また、 model_params の中で、思考トークンを 0 に固定しており、これによりGemini 2.5 Flash のように思考の過程が存在するモデルではコスト面・速度面で恩恵を受けられます(もちろんタスクによっては思考トークンを割いたほうがいいこともあると思います)

ちゃんとレスポンスが返ってきました。レスポンスも速く、良い感じです。
構造化して出力する
このままレスポンスをJSON文字列にしてもらおうと思います。
このためにはまずプロンプトを下記のように変更し、出力の形式を指定します。
prompt => CONCAT('この質問に答えてください。質問:', title, '\n 出力はJSONとし、answer と title をキーとしてください'),
そして、モデルのパラメータに response_mime_type として、 application/json を指定します。
model_params => JSON '''
{
"generation_config": {
"temperature": 0.1,
"max_output_tokens": 1024,
"thinking_config": {"thinking_budget": 0},
"response_mime_type": "application/json"
}
}
(ちなみにこの指定単体でもそれっぽいJSONを返すようになります)
まとめると下記です。
SELECT
title,
AI.GENERATE(
prompt => CONCAT('この質問に答えてください。質問:', title, '\n 出力はJSONとし、answer と title をキーとしてください'),
connection_id => '{{PROJECT_ID}}.{{DATASET_NAME}}.llm_connection',
endpoint => 'gemini-2.5-flash',
model_params => JSON '''
{
"generation_config": {
"temperature": 0.1,
"max_output_tokens": 1024,
"thinking_config": {"thinking_budget": 0},
"response_mime_type": "application/json"
}
}
'''
)
FROM
`{{PROJECT_ID}}.{{DATASET_NAME}}.test_data_for_llm`
これにより、JSONでレスポンスを得ることが出来ます!

そのまま BigQuery で PARSE_JSON 関数を用いてJSON型として扱うことも可能です。
カラムとして出力してもらう
さらにいうと、直接カラムに出して貰うこともできます。
やり方は、下記のような指定を足すだけです。
output_schema => 'title STRING, answer STRING'
クエリ全体としてはこうなります。
SELECT
title,
AI.GENERATE(
prompt => CONCAT('この質問に答えてください。質問:', title),
connection_id => '{{PROJECT_ID}}.{{DATASET_NAME}}.llm_connection',
endpoint => 'gemini-2.5-flash',
model_params => JSON '''
{
"generation_config": {
"temperature": 0.1,
"max_output_tokens": 1024,
"thinking_config": {"thinking_budget": 0}
}
}
''',
output_schema => 'title STRING, answer STRING'
)
FROM
`{{PROJECT_ID}}.{{DATASET_NAME}}.test_data_for_llm`
この指定により、answer および title がカラムとして出力されるようになります。
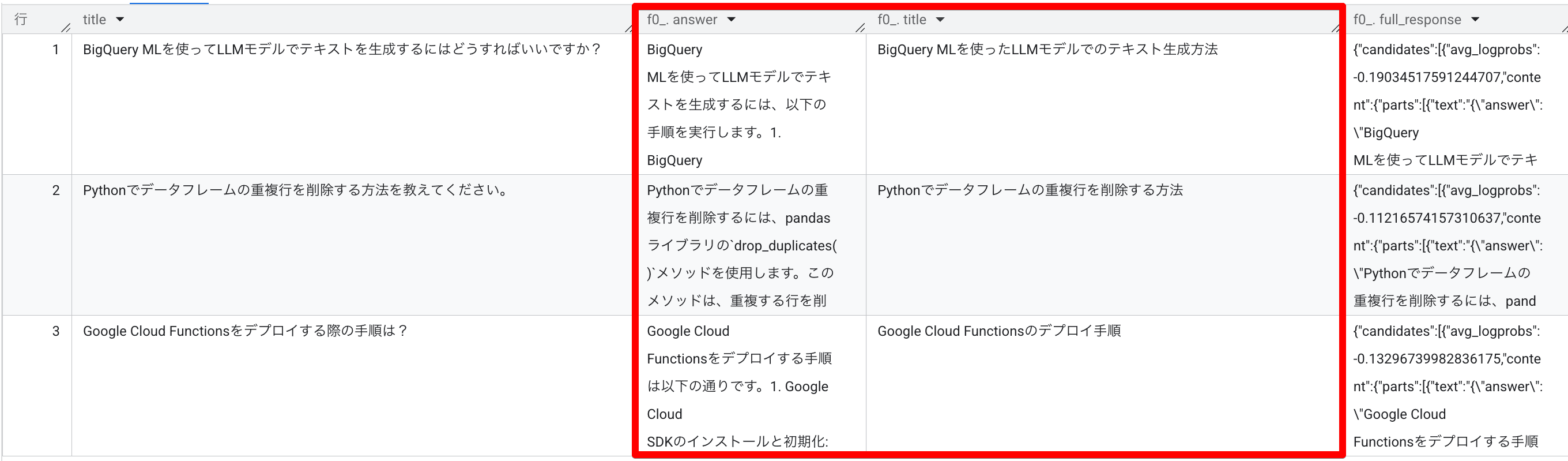
title のほうは要約したタイトルにしてくれていますね。このあたりは細かくプロンプトで指示することも可能かと思います。
AI.GENERATE 関数についての所感
と、このような感じで Gemini x BigQuery なシーンでは非常に使いやすい関数となっている印象です。
まだプレビュー版なのでさすがに本番系をどんどん置き換えて…みたいなことをするのは難しいかなと思いますが、GAとなり次第積極的に置き換えていけると良いかと思っています。
特に思考トークンのバジェット設定と、形式指定は新時代型の前処理においては非常に有効なのではないかと思いました。思考トークンはよりコストの高い「出力トークン」の枠組みの中で課金対象となるので、速度とコストの両面の観点で必要ないシーンでは切ってしまったほうが良いように思います。
まとめ
今回はプレビュー版ながら便利に使える AI.GENERATE 関数について扱いました。
すでに ML.GENERATE_TEXT 関数を使っている場合などは特に一度試しておくのが良いかと思います。
前述の通りまもなく Gemini 1.5 Flash が廃止を予定されているので、リージョンの制約等で Gemini 2.5 Flash へと移行を予定されている方もいるのかな?と思いますが、 ML.GENERATE_TEXT だと null 祭りになる…などの悩みを抱えている場合にもう一つのオプションとして知っておくと良いかと思います。
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 データ戦略チーム
アプリケーションからインフラ、ネットワーク、データエンジニアリングまで幅広い守備範囲が売り。最近はデータ基盤の構築まわりに力を入れて取り組む。 主な実績として、M-1グランプリ敗者復活戦投票システムのマルチクラウド化等。




