Dataform × BigQuery のトランザクションでアトミックなテーブル更新を実現
BigQuery のテーブル更新をアトミックに行いたい
私が現在所属しているチームでは、DWH として Google Cloud の BigQuery を利用しており、Looker や Looker Studio を繋げてビジネスユーザーに分析を行ってもらっています。
また、データの変換については、BigQuery と相性が良い Dataform を利用して SQLX を用いてコード管理しています。
そういった中で、最近ビジネスユーザーから、「テーブル更新が行われているタイミングで特定の期間のデータが欠損していることがある」と伺い、今回はそれに対応するために行った内容についてお話しします。
BigQuery のトランザクション機能
データ欠損の問題を解決するために、まず BigQuery のトランザクションという機能を活用します。
BigQuery のトランザクションは、複数の DML ステートメントを「すべて成功するか、すべて取り消すか」の一つのかたまりとして扱うための仕組みです。
マルチステートメントクエリの中で BEGIN と COMMIT を使い、途中で失敗した場合は変更がロールバックされます。
基本構文は以下のような形になります。
BEGIN TRANSACTION;
-- 複数の DML(INSERT / UPDATE / DELETE / MERGE など)
COMMIT TRANSACTION; -- 失敗時は ROLLBACK される
従来の OLTP データベースでは当たり前の機能ですが、いわゆる OLAP データベースである BigQuery でも2023年1月に GA となった比較的新しい機能になります。
機能の詳細については、「Multi-statement transactions」に詳細が書いてあるので、興味がある方はぜひ確認してみてください。
Dataform でトランザクションを活用して欠損を防ぐ
このトランザクション機能を、Dataform と組み合わせることで、ワークフロー内で起こってしまうデータ欠損の問題を解決できます。
Dataform では、テーブルごとに増分更新 (incremental) を定義でき、増分だけを効率よくテーブルに反映できます。
さらに pre_operations と post_operations を使えば、BigQuery のトランザクションをテーブル更新のワークフロー内に組み込んでアトミックな更新を実現できます。
incremental とは?
incremental とは、毎回すべてのデータを作り直すのではなく、「新しく追加された部分」や「変更があった部分」だけを取り込む Dataform におけるテーブルタイプの一つです。
これにより、必要な分だけを更新するため、処理時間とコストを大幅に削減できます。
例えば、「昨日のデータだけを追加する」「最後に処理した時刻より新しいデータだけを取り込む」といった使い方をします。
設定方法は簡単で、SQLX ファイルの config ブロック内のテーブルタイプを以下のように設定するだけです。
type: "incremental"
pre_operations / post_operations とは?
pre_operations は、Dataform において「メインの処理を実行する前に行いたい準備作業」を指定する場所です。
例えば、「設定値を定義する」「トランザクションを開始する(BEGIN TRANSACTION)」などを書きます。
同じように、post_operations は「メインの処理が終わった後に行いたい後片付け」を指定する場所で、「トランザクションを確定する(COMMIT TRANSACTION)」などを書きます。
これらの機能を組み合わせることで、ワークフロー内で起こるデータの欠損を防ぎつつ、効率よくデータの更新を行うことができるようになります。
次に、実際の実装例とその挙動について確認してみます。
トランザクションの有無による比較
実際にトランザクションを使わない場合と使う場合を比較して、データ欠損がどう変わるか確認してみました。
まず、今回検証に使うための2つのテーブルを準備します。
下記のクエリで source テーブルと destination テーブルを全く同じ内容で作成します。
CREATE OR REPLACE TABLE [データセット名].demo_source AS (
SELECT
num AS id,
CONCAT("user_", CAST(num AS STRING)) AS name,
DATE_SUB(CURRENT_DATE(), INTERVAL MOD(num, 10) DAY) AS updated_at
FROM
UNNEST(GENERATE_ARRAY(1, 100)) AS num
);
CREATE OR REPLACE TABLE [データセット名].demo_destination AS (
SELECT
num AS id,
CONCAT("user_", CAST(num AS STRING)) AS name,
DATE_SUB(CURRENT_DATE(), INTERVAL MOD(num, 10) DAY) AS updated_at
FROM
UNNEST(GENERATE_ARRAY(1, 100)) AS num
);
これで、それぞれ100件の検証用テーブルが作成できました。
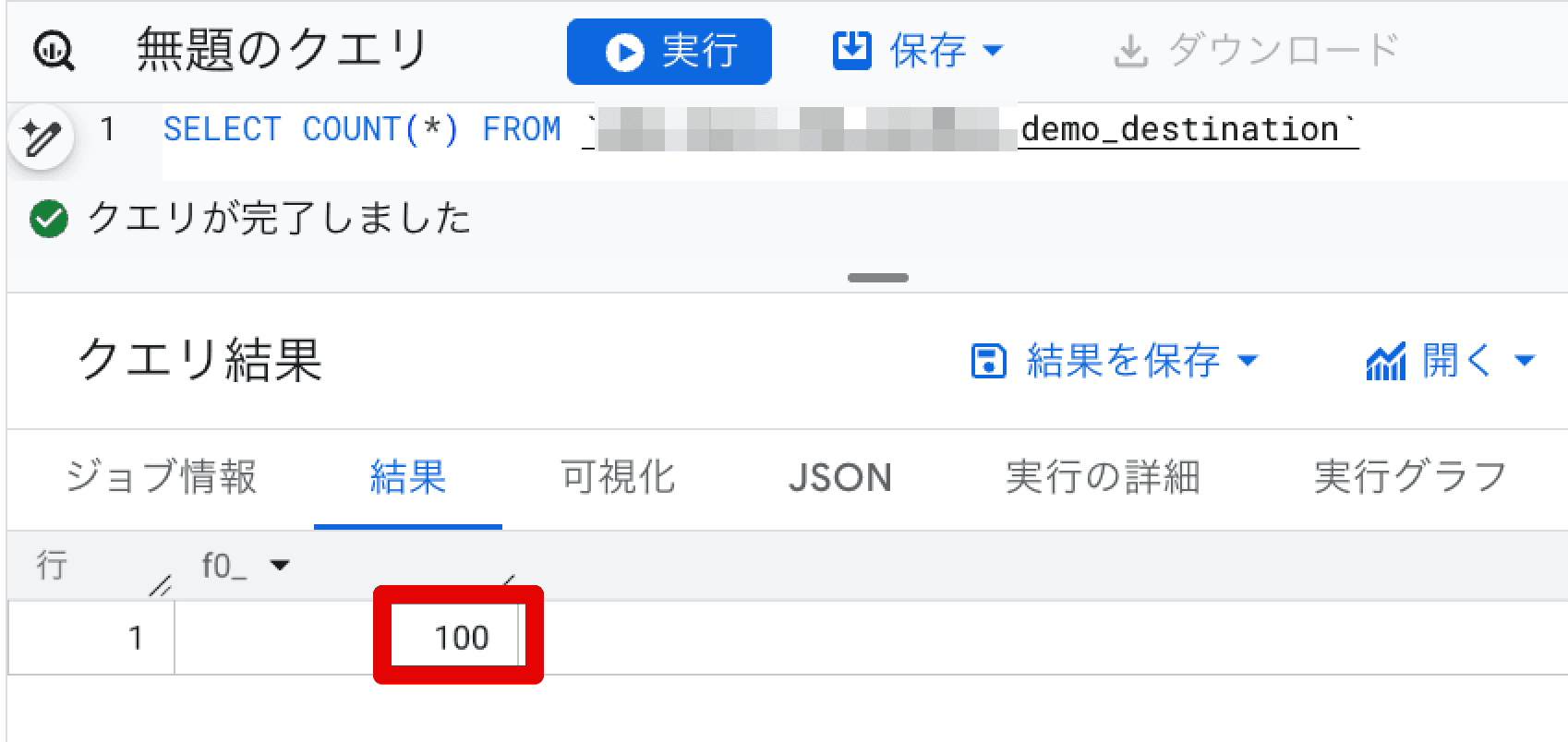
次に今作成した destination テーブルに対して、incremental な更新を行いトランザクションの有無による挙動の違いを確認してみます。
パターン1:トランザクションを使わない場合
まずは、下記のような SQLX を定義して挙動の確認を行います。
config {
type: "incremental",
database: "[プロジェクト名]",
schema: "[データセット名]",
name: "demo_destination",
columns: {
id: "ID",
name: "名前",
updated_at: "更新日時"
}
}
SELECT
id,
name,
DATE_ADD(updated_at, INTERVAL 1 DAY) AS updated_at
FROM
${ref("[プロジェクト名]", "[データセット名]", "demo_source")}
WHERE
updated_at > update_baseline_date
AND (
WITH base1 AS (
SELECT * FROM UNNEST(GENERATE_ARRAY(1, 10000)) AS id1
),
base2 AS (
SELECT * FROM UNNEST(GENERATE_ARRAY(1, 10000)) AS id2
)
SELECT COUNT(*) > 0
FROM base1
CROSS JOIN base2
)
pre_operations {
${
when(incremental(),
`DECLARE update_baseline_date DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 5 DAY);
DELETE FROM ${self()} WHERE updated_at > update_baseline_date;`,
`DECLARE update_baseline_date DEFAULT DATE("2000-01-01");`
)
}
}
処理の内容としては、100件のうち、ちょうど50件に対して、いったんデータを削除して、source テーブルから「更新日時」カラムをアップデートしたものを追加挿入するという処理です。
なお、いったん削除された後に、十分な時間を確保できるように、少し重ための処理を WHERE 句に入れています。
上記の SQLX をコンパイル & 実行し、実行中にレコード数を確認してみると、下記のように pre_operations 内に定義されていた DELETE が実行され、50件しかデータがないのが確認できます。
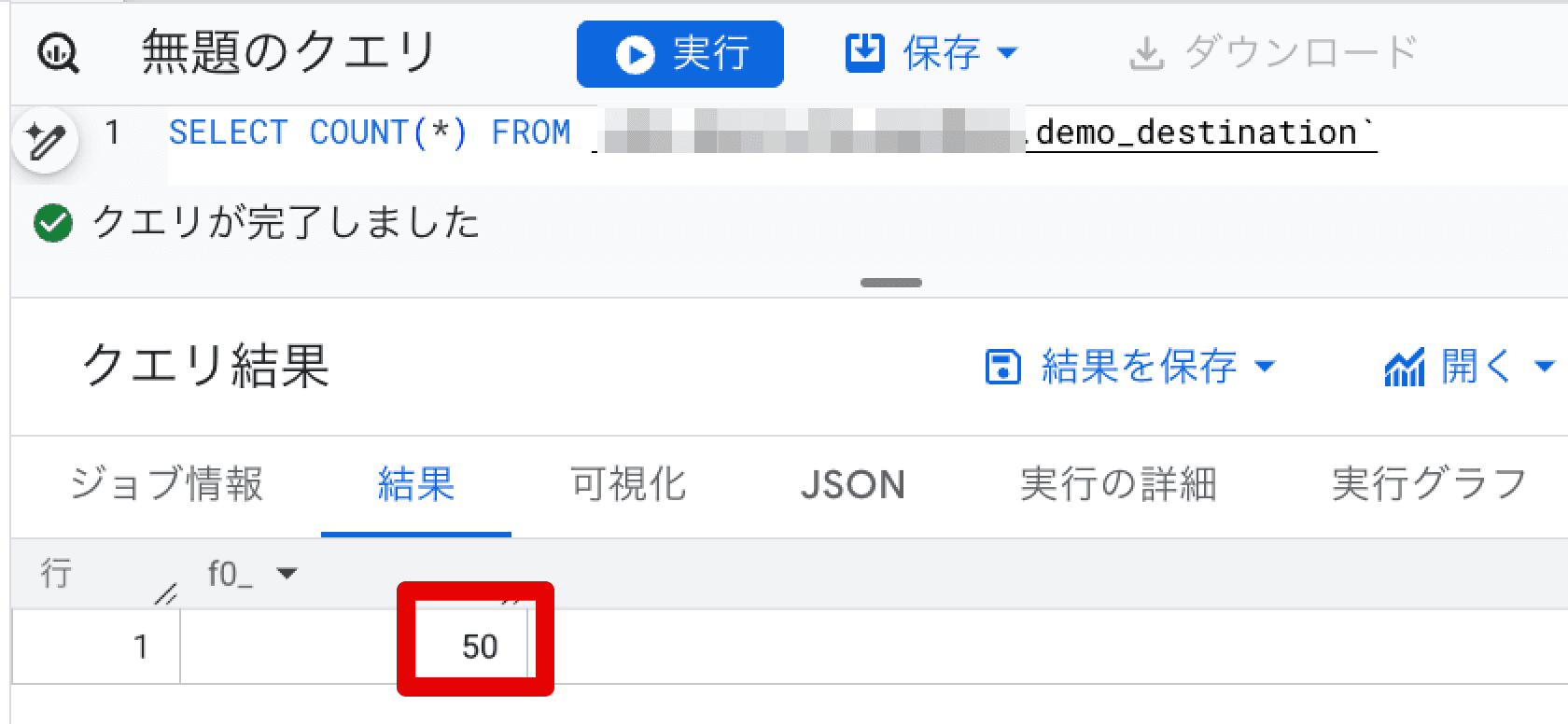
これだと、実運用を考えたときに、更新に時間のかかるテーブルの場合は一時的にデータが少なく見えるなど、様々な問題の原因になってしまいます。
パターン2:トランザクションを使う場合
次に、トランザクションを用いる場合の SQLX は以下のようになります。
config {
type: "incremental",
database: "[プロジェクト名]",
schema: "[データセット名]",
name: "demo_destination",
columns: {
id: "ID",
name: "名前",
updated_at: "更新日時"
}
}
SELECT
id,
name,
DATE_ADD(updated_at, INTERVAL 1 DAY) AS updated_at
FROM
${ref("[プロジェクト名]", "[データセット名]", "demo_source")}
WHERE
updated_at > update_baseline_date
AND (
WITH base1 AS (
SELECT * FROM UNNEST(GENERATE_ARRAY(1, 10000)) AS id1
),
base2 AS (
SELECT * FROM UNNEST(GENERATE_ARRAY(1, 10000)) AS id2
)
SELECT COUNT(*) > 0
FROM base1
CROSS JOIN base2
)
pre_operations {
${
when(incremental(),
`DECLARE update_baseline_date DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 5 DAY);
BEGIN TRANSACTION;
DELETE FROM ${self()} WHERE updated_at > update_baseline_date;`,
`DECLARE update_baseline_date DEFAULT DATE("2000-01-01");`
)
}
}
post_operations {
${
when(incremental(),
`COMMIT TRANSACTION;`,
''
)
}
}
この場合、先程確認した pre_operations にトランザクションの開始の合図である BEGIN TRANSACTION を記述し、post_operations 内で COMMIT TRANSACTION を記述するようにします。
その他の内容については、基本的に先程のクエリと同じです。
先程同様にクエリ実行中にレコード数を確認したところ、この段階では、DELETE 処理の影響が外部に反映されておらず(トランザクションがコミットされていないため)、一時的なデータの欠損は一切発生していませんでした。
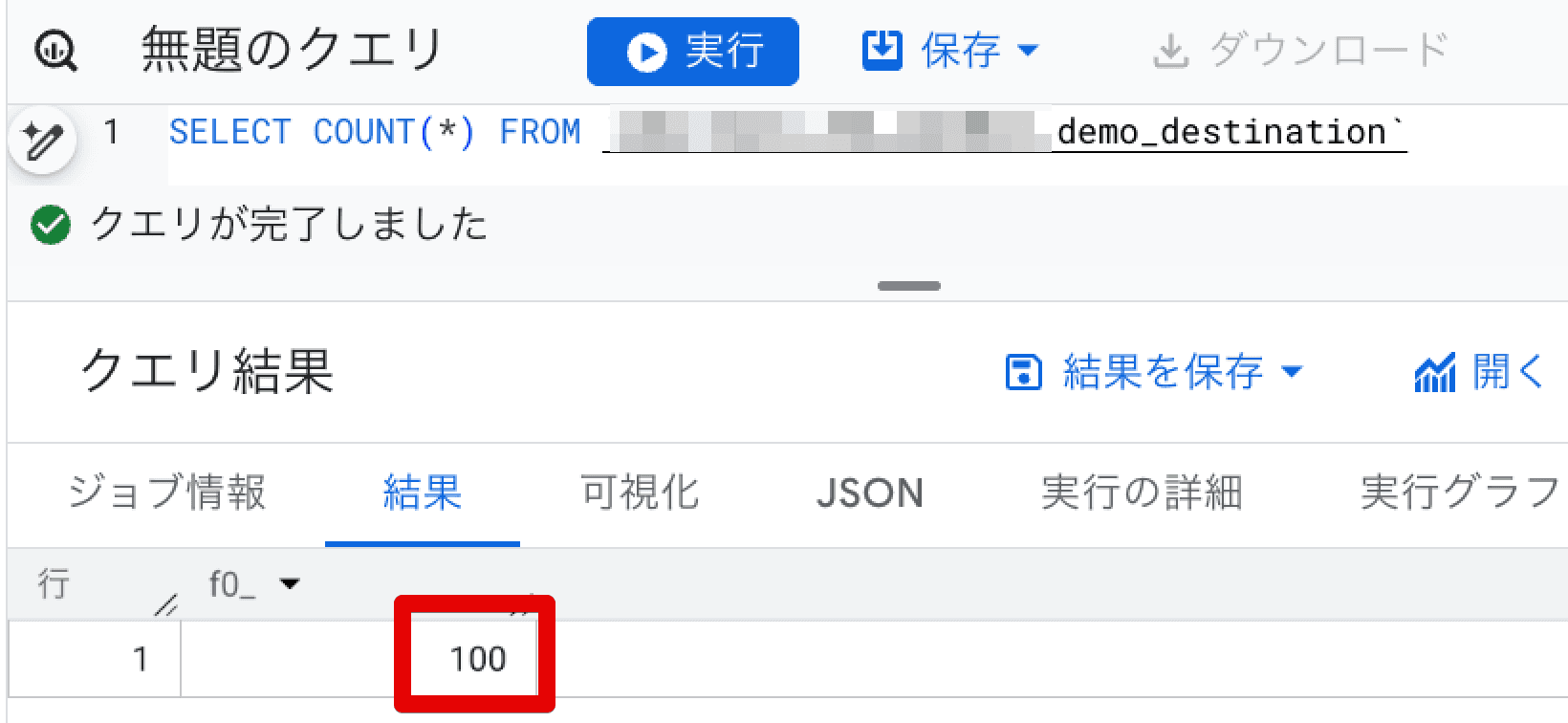
これは、トランザクション内で DELETE や INSERT といった複数ステートメントを実行し、全ての処理が完了した後に、アトミックにテーブルに反映されるためです。
このように、Dataform の各種機能と BigQuery のトランザクションを利用することで、いかなるタイミングでもテーブル内のデータに欠損を発生させることなく、テーブルを更新することができました。
まとめ
本記事では、Dataform と BigQuery を組み合わせて、テーブル更新をアトミックに行う方法について解説しました。
pre_operations と post_operations を活用してトランザクションを実装することで、incremental な更新処理中に一時的なデータ欠損が発生することを防ぐことができます。
これにより、ビジネスユーザーがいつテーブルを参照しても、常に完全なデータを取得できる安定した環境を構築することが可能になります。
今後も、データを扱う際には常にユーザー目線に立ち、安心して活用できるワークフローを構築していくことを心がけていきたいと思います。
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 データ戦略チーム
グループ全体の統合的なデータ基盤の構築・データ分析の支援に従事している。 動画配信・テレビの視聴データ分析等で身につけた幅広い知識を活かして日々奮闘中!




