NULLも含めて正しく判定!「IS DISTINCT FROM」活用術
否定条件でNULLまで消えてしまう SQLの除外判定でハマりやすい罠
データ分析やシステム開発でSQLを書く際、データベース製品の種類に関わらず共通して悩ましいのが NULLの扱い です。
我々のチームでも日々の業務でSQLを書く機会は多いのですが、このNULLの扱いでたまにハマってしまうことがあります。
例えば、少し特殊な例かもしれませんが、ユーザー一覧から 「ゲストユーザー(guest)以外(未設定も含む)を抽出したい」 というシーンを想像してみてください。
ここで WHERE user_type <> 'guest' と書くと、ユーザータイプが NULL(未設定)のデータまでごっそり消えてしまい、集計結果が想定と異なることになってしまいます。
「NULLも含めて除外判定したいけど、毎回 OR user_type IS NULL を書くのは面倒くさい…」
そんな時に役立つのが、今回紹介する IS DISTINCT FROM です。
SQLにおけるNULLの罠
まず、SQLを書く上で避けて通れないのが 「3値論理」 の理解です。
TRUE、FALSE に加えて NULL(UNKNOWN)が存在することで、直感とは異なる挙動をしてしまうことがあります。
このあたりの詳細については、以下の過去記事で解説していますので、「あれ、なんで消えるんだっけ?」という方はまずはこちらをご覧ください。
意図せずNULLな行を除外してしまうSQLからNULLを理解する
上記の記事でも触れていますが、通常、= や <> などの比較演算子は、片方が NULL だと結果も NULL(UNKNOWN) になってしまいます。
一方で、よく使う IS NULL や IS NOT NULL だけは例外で、これらは対象がNULLかどうかを判定し、明確に TRUE か FALSE を返します。
先ほどの WHERE user_type <> 'guest' の例でデータが消えてしまうのは、user_typeが NULL の場合に演算結果が TRUE ではなく NULL になり、条件に合致しないと判断されるためです。
そのため、先程の例のような場合には OR user_type IS NULL を併用して、「NULL と比較の場合でも結果をTRUEにする」必要がありました。
しかし、毎回 OR ... IS NULL を書くのは少し手間かと思います。
その際に利用できるのが、今回紹介する IS DISTINCT FROM です。
解決策:IS DISTINCT FROM
IS DISTINCT FROM は、「NULLをひとつの値として扱い、比較対象と区別できるか(Distinctかどうか)」 を判定してくれる便利な演算子です。
この構文は標準SQLで定義されているため、特定のDB製品独自のものではありません。
我々のチームでは主にデータ分析基盤として BigQuery を使っていますが、BigQueryに限らずPostgreSQLなど多くのRDBMSでもサポートされています(※一部未サポートのDBもあります)。
通常の比較演算子と IS DISTINCT FROM の違いを整理すると、以下のようになります(左辺をカラム、右辺を 1 とした場合)。
| カラムの値 | 比較式: <> 1 | 比較式: IS DISTINCT FROM 1 |
|---|---|---|
1 | FALSE | FALSE (区別できない=同じ) |
2 | TRUE | TRUE (区別できる=違う) |
NULL | NULL (UNKNOWN) | TRUE (区別できる=違う) |
ご覧の通り、<> が NULL を返してしまうのに対し、IS DISTINCT FROM は IS NULL 判定と同様に、NULLの場合でも TRUE(区別できる=違うもの) という明確な真偽値を返してくれます。
つまり、「NULLも含めてFALSE(一致しない)と判断したい」、言い換えれば 「特定の値以外(NULL含む)を抽出したい」 という場面で非常に強力な武器になります。
ちなみに、BigQueryの公式ドキュメントにも記載がありますので、詳細な仕様が気になる方はこちらもご参照ください。
実際に試してみる
百聞は一見に如かずということで、実際にクエリを叩いて挙動を確認してみましょう。
弊社では普段 BigQuery を利用しているため、ここではBigQuery上での実行結果を掲載しますが、対応している他のDBでも同様の挙動になるはずです。
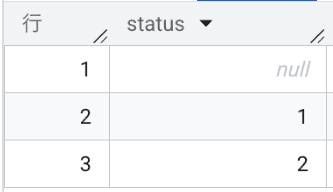
まずは、1, 2, NULL を持つ一時テーブルを作ります。
WITH data AS (
SELECT 1 AS status UNION ALL
SELECT 2 AS status UNION ALL
SELECT NULL AS status
)
SELECT * FROM data ORDER BY status;
実行結果:
1. 通常の不等価演算子(<>)の場合
まずは、「ステータスが1ではない」ものを通常の <> で抽出してみます。
WITH data AS (
SELECT 1 AS status UNION ALL
SELECT 2 AS status UNION ALL
SELECT NULL AS status
)
SELECT
*
FROM
data
WHERE
status <> 1;
実行結果:
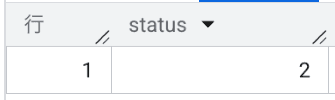
予想通り、3値論理の原則に従って NULL の行が消えてしまい、2 だけが残りました。
2. IS DISTINCT FROM を使った場合
次に、IS DISTINCT FROM を使ってみます。
WITH data AS (
SELECT 1 AS status UNION ALL
SELECT 2 AS status UNION ALL
SELECT NULL AS status
)
SELECT
*
FROM
data
WHERE
status IS DISTINCT FROM 1;
実行結果:
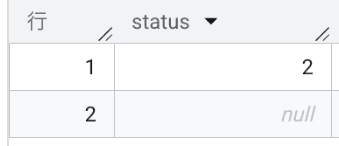
今度は期待通り、1 以外の値として 2 と NULL の両方が抽出されました!
どんな場面で役立つ?
この挙動は、例えば、以下のようなシーンで特に役立ちます。
- 除外フィルタリング
- 冒頭の例のように、「特定の値(除外対象)以外」を抽出したいパターンです。
- 「ゲストユーザー(guest)以外(未設定も含む)を抽出したい」という場合、
WHERE user_type IS DISTINCT FROM 'guest'と書けば、NULL(未設定)を含むすべての一般ユーザーをシンプルに抽出できます。
- データの変化・切り替わりの検知(Lag関数との組み合わせ)
- 時系列データで「値が変わったタイミング」を検知したい場合に非常に有効です。
- 例えば、毎分の番組情報が並んでいるデータで「番組が切り替わったタイミング(開始時刻)」にフラグを立てたいとします。通常はウィンドウ関数の
LAGを使って「1行前の番組名」を取得し、現在の行と比較します。 - ここで問題になるのが 「データの先頭行」 です。先頭行には「前の行」が存在しないため、
LAG関数の結果はNULLになります。 - このとき、単純に
CASE WHEN program_name <> prev_program_name ...と書いてしまうと、先頭行は番組A <> NULLという比較になります。これは SQL の仕様上NULLとなるため、番組の開始(変化)として検知されず、フラグが立ちません。 - そこで
IS DISTINCT FROMの出番です。
CASE WHEN program_name IS DISTINCT FROM prev_program_name ...と書けば、番組A(現在)とNULL(直前なし)の比較もTRUE(異なる)と判定されるため、データの先頭も漏らさず「切り替わり」として検知 できます。
- CASE文での分岐
- 条件分岐で
NULLを個別にケアするOR column IS NULLのような記述を減らし、可読性を高めることができます。
- 条件分岐で
まとめ
今回は、SQLにおける IS DISTINCT FROM の活用法をご紹介しました。
- SQLの
<>はNULLを除外してしまう。 IS DISTINCT FROMはIS NULLと同様にNULLを値として扱い、明確にTRUE/FALSEで比較してくれる。- BigQueryをはじめ、PostgreSQLなど多くのDBで利用可能。
使える状況は比較的限られているので、ニッチな機能ではあるのですが、活用できるとクエリの安全性と可読性が上がるため、知っていて損はない構文かと思います。
今年も残りあと僅かですが、引き続き少しでも皆さんのお役に立てるような情報を発信していきたいと思います!
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 データ戦略チーム
グループ全体の統合的なデータ基盤の構築・データ分析の支援に従事している。 動画配信・テレビの視聴データ分析等で身につけた幅広い知識を活かして日々奮闘中!




