PaLM 2をLangChainで使う
PaLM 2 APIをLangChain越しに活用するには
PaLM 2 APIについて
「自前のデータを踏まえた回答をLLMから得るには」に始まり、最近LLMに関する投稿を続けてきましたが、その中で、 LangChainを使えば多様なLLMを簡単に使用できますし切り替えも楽 です、ということを言ってきました。
そこで今回は、Google Cloudで最近GA(一般公開)となった、 PaLM2 APIをLangChainを通して活用する方法 についてまとめていきます。今週火曜日はGenerative AI Summitでしたからね。LLM真夏の大冒険中の皆様におかれましても自ずと関心が高まっているはずです。
まずはPaLM 2 APIについてみていきましょう。
PaLM 2 APIはGoogle Cloudで提供されているLLM(大規模言語モデル)で、Google I/O 2023で発表されていました。
概要としてはそのタイミングで出された Google Japan Blogの PaLM 2のご紹介の記事 が最も分かりやすいかと思います。
この記事の中の
PaLM 2 には、Gecko、Otter、Bison、Unicorn という 4 つのサイズがあります。Gecko は非常に軽量なため、モバイル 端末で動作し、オフラインの状態でも、デバイス上の優れたインタラクティブ アプリケーションを実現するのに十分な速さです。
このあたりは拾っておくといいことがあるかもしれません。(bisonとかgeckoって何だよ、みたいな疑問が湧くタイミングが多分あるので)
そして 「日本語対応しました!」 と火曜日のGenerative AI Summitで発表されたというわけです。
実際どこで確認ができるか…というと、Google Cloudのコンソールを開いて、「Vertex AI」の「Model Garden」を見ると「PaLM 2 for Text」の文字がドーンと出てきます。
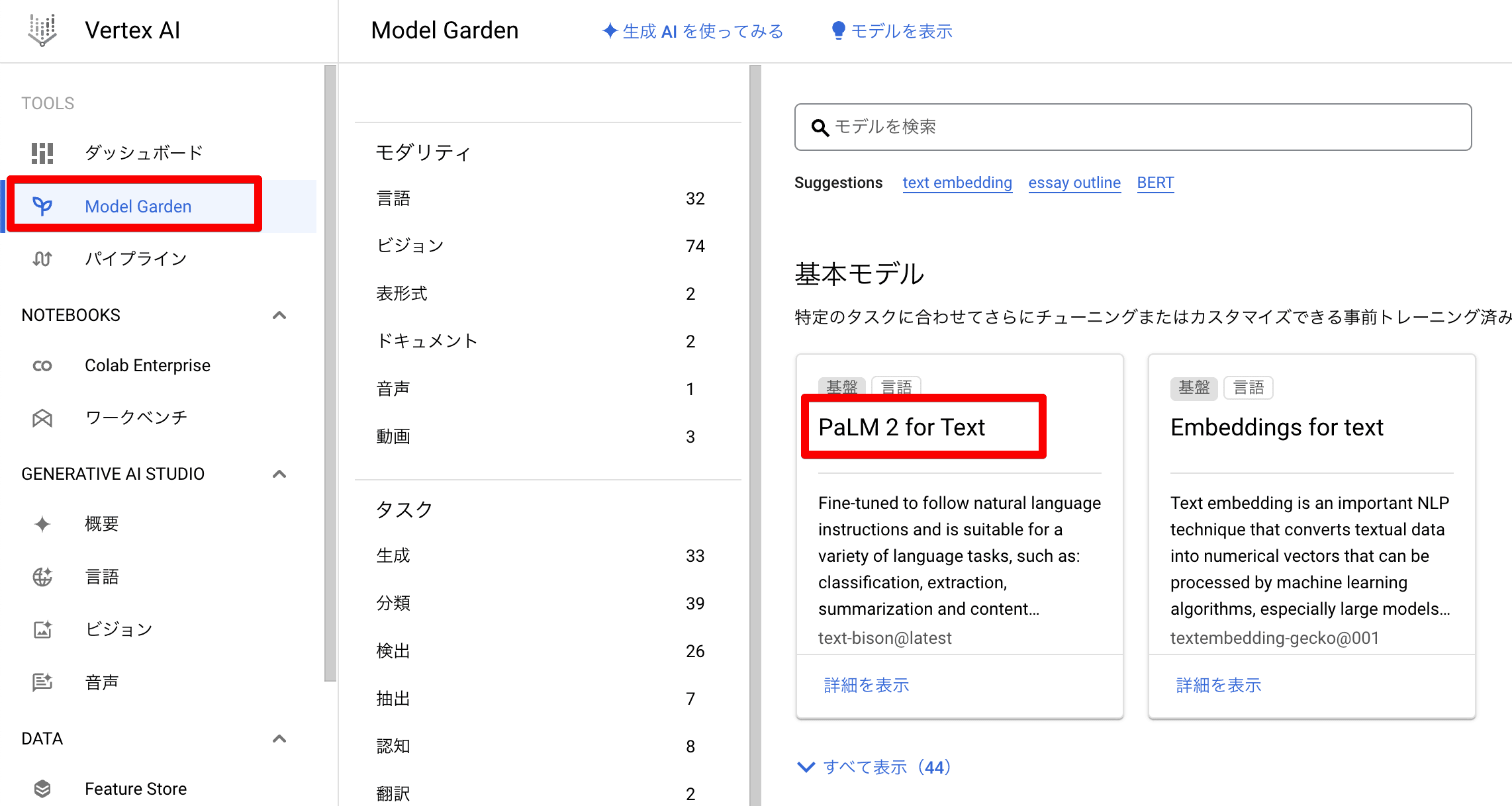
これが一番基本となるモデルです。
その他にもめぼしいところで、Chat向けの PaLM 2 for Chat や、コード補完・コード生成を担うPaLM 2ベースの Codey 、このあたりは真夏の大冒険中に触っておいたほうが良さそうです。
それぞれのモデル名としては
PaLM 2 for Text: text-bison
PaLM 2 for Chat: chat-bison
Codey for Code Completion: code-gecko
Codey for Code Generation: code-bison
となります。先ほどの引用にあった、geckoやbisonの文字が後ろについていますね。
基本的にコード中ではこれらのモデル名を使用します。
このVertex AIに関しては各サービスの統合等あってここ数年で一気に大きくガラリと変わって私としても色々と手探りで触っているところですが、
例えば、Model Gardenの「PaLM 2 for Chat」を開くと「プロンプト設計を開く」というボタンがあって、
コンテキストと例示を出した上で回答を貰うことができます。

プロンプト設計が出来るものは限られていますが、 APIコードも表示できるのでめちゃくちゃ試す敷居が低いです。
LangChainとPaLM 2
そんなPaLM 2ですが、やはり実用に寄せていこうと思うと、LangChainと連携させて使いたくなります。
そしてさすがに開発が盛んなだけあって、もう既に簡単に使用できるようになっています。
ここではLangChainでPaLM 2を使用するために必要な内容と公式ドキュメントのリンクをまとめておきます。
使用の前に、 google-cloud-aiplatform をpipなりpoetryなりで追加しておく必要があることに御注意下さい。
LLM
langhcain.llms から使用する場合は VertexAI をインポートします。
from langchain.llms import VertexAI
としてimportした上で、
model = VertexAI(model_name=MODEL_NAME, top_p=0.8, top_k=40, temperature=0.2)
のように使用します。
このとき、プロジェクトの指定はデフォルト認証情報(ADC)に基づくことに注意が必要です。(2023/08/22時点では project=PROJECT_NAME のように指定してもADCのプロジェクトのほうが優先されていました)
ADCについてはGoogle Cloudの「アプリケーションのデフォルト認証情報を設定する」のページが参考になります。個人的にこのページは非常に重要だと思います。
modelについては、PaLM 2 API for Text( text-bison )のほかにコード補完のCodey for Code Completion( code-gecko )、コード生成のCodey for Code Generation( code-bison )も使用できます。
本記事では、折角なのであとでCodey for Code Generationを試してみようと思います。
使用する前に LangChainのPaLM2をLLMモデルを使用するための公式ドキュメント に目を通しておくと良いかと思います。
Chat Model
PaLM 2 for Chatを使う場合は
from langchain.chat_models import ChatVertexAI
chat = ChatVertexAI()
のようにimportして活用します。
PaLM 2 API for Textに可能な限り全文脈を放り込んでいく方式でも文脈を組んだ回答が得られるかと思いますが、基本的にはChatでの活用の場合はこちらを使った方がコードの見通しがよくなるかと思います。
LangChainのChat ModelsのPaLM 2公式ドキュメント もご参照下さい。
Embedding
自前データを活用する際に欠かせないのがEmbeddingですが、こちらも Vertex-AI text-embeddings API が用意されており、LangChain越しに叩くことが可能です。
from langchain.embeddings import VertexAIEmbeddings
embeddings = VertexAIEmbeddings()
のように VertexAIEmbeddings をimport し、 embeddings.embed_query("本日は晴天なり") のように使用します。
こちらも LangChainのEmbeddingsのPaLM 2公式ドキュメント があります。
Matching Engine
そして、調べているとなんとMatching EngineにもLangChainは対応していて、これはかなり推せるのではないかと思っています。
Matching Engineについては 公式のMatching Engineの概要ページ を参照いただくのが最も確実かと思いますが、要するにベクトル表現に基づくマッチングを行うためのエンジンです。今めちゃくちゃ検証したい対象です。おそらく近々記事を書くことになりそうな気がします。
全く触れていないのですが、LangChainのMatchingEngineの公式ドキュメントによれば、エンドポイントへのデプロイまで含めてサポートしているようで、夢が膨らみますね。
実際にCode Generationしてみる
ここまで基本的なLangChainとPaLM 2 APIの組み合わせ方について紹介してきました。
多くの大冒険中の方々はLangChainを使った何かを持っているかと思うので、基本的には上記に沿ってモデルを切り替えるだけかと思いますが、それだけだとちょっと味気ないので、実際に超・簡易スクリプトでCodeyを叩いてCode Generationしてみます。
Codey for Code Generation(code-bison)を実行する
ここではcsvファイルから適当に基礎分析を行った結果をもらうためのコードを作って貰いましょう。
プロンプトとしては下記を与えてみます。
Pythonで数字が完全数かどうかを判定する関数を書いて下さい。
この場合、質問もベタ打ちのコードとしては、
from langchain import LLMChain, PromptTemplate
from langchain.llms import VertexAI
input_text = "Pythonで数字が完全数かどうかを判定する関数を書いて下さい。"
template = """
Human: {user_message}
AI:
"""
prompt = PromptTemplate(input_variables=["user_message"], template=template)
model = VertexAI(model_name="code-bison", top_p=0.8, top_k=40, temperature=0.2, max_output_tokens=1000)
chain = LLMChain(llm=model, prompt=prompt, verbose=False)
res = chain.run({"user_message": input_text})
print(res)
これだけでOKです。
すると出力は…
def is_perfect_number(n):
"""
数字が完全数かどうかを判定する関数
Args:
n: 判定する数字
Returns:
True: 完全数の場合
False: 完全数でない場合
"""
if n <= 1:
return False
# 約数の和を計算
sum_of_divisors = 0
for i in range(2, int(n ** 0.5) + 1):
if n % i == 0:
sum_of_divisors += i
sum_of_divisors += n // i
# 約数の和がnと等しい場合、完全数
return sum_of_divisors == n
となりました。
完全数とは自身を除く全ての約数の和が自身と一致する数…ですが、これ、実は 1を足せてないので間違ったコードです。。 残念
LLMの出力を鵜呑みにしてはいけません…
プロンプトを変えてみます。例示を加えつつ、確認したい旨も伝えてみます。
完全数とは自身を除く全ての約数の和が自身と一致する数です。例えば、6は1, 2, 3, 6を約数として持つので、自身である6を除いた和は1+2+3=6となり、自身と一致することから完全数とわかります。Pythonで数字が完全数かどうかを判定する関数を書いて下さい。また、6が完全数と判定されることを確認したいです。
出力はこうなりました。
def is_perfect_number(n):
sum = 0
for i in range(1, n):
if n % i == 0:
sum = sum + i
return (sum == n)
print(is_perfect_number(6))
急にコードが簡素極まりなくなっていますが、実際これはよさそうです。
当たり前の話ですが、 コード補助にしても生成にしても出力に対して目を通してから利用する必要はありそうですね。
あるいはテストケースを利用したpromptが有効だったりするのだろうか… 🧐
まとめ
今回はPaLM 2をLangChainから利用する方法についてまとめていきました。
LangChainを使うとモデルの切り替えが容易で非常に助かります。
一方で、LLMモデルは現状各社からどんどん出てきていますが、各モデルの強いところ・弱いところまで認識しようと思うとなかなか骨の折れる検証が必要になりそうです。
皆さんはどうやってモデル選択しているんでしょうね?各社のモデルに対しての知見を共有し合う場が欲しい昨今です。
AUTHOR

朝日放送グループホールディングス株式会社 デジタル・アーキテック局 データ戦略チーム
アプリケーションからインフラ、ネットワーク、データエンジニアリングまで幅広い守備範囲が売り。最近はデータ基盤の構築まわりに力を入れて取り組む。 主な実績として、M-1グランプリ敗者復活戦投票システムのマルチクラウド化等。




